Data science benchmarks for AI systems view markdown
Here are some benchmarks focusing on getting insight directly from data using LLMs / LLM agents (requires the models to interact with the data through code). I find these compelling, as they are really hard tasks, useful for real-world applications, and also an extensible stepping stone to accelerate scientific discovery.
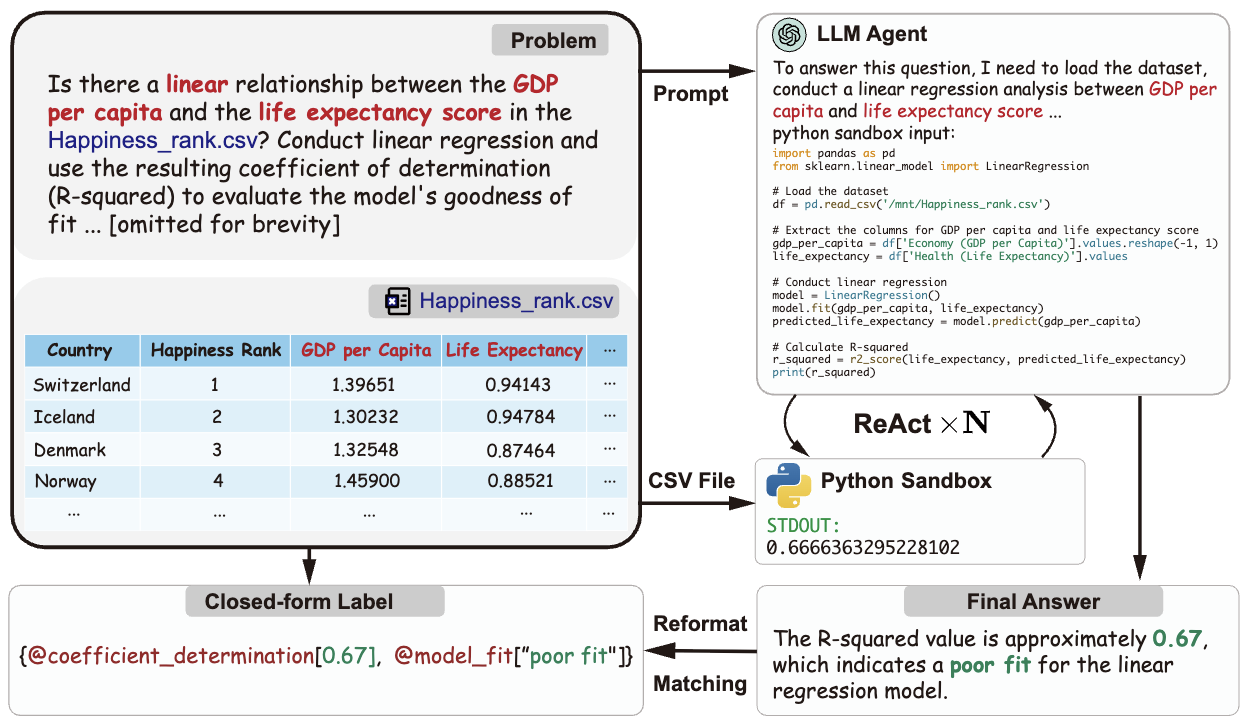
ScienceAgentBench (chen…huan sun, 2024) - 102 scientific coding tasks (from 44 papers in 4 disciplines validated by 9 subject-matter experts)
- target output for every task is a self-contained Python file
- each task has (a) task instruction, (b) dataset info, (c) expert-provided info and (d) a groundtruth annotated program

AutoSDT: Scaling Data-Driven Discovery Tasks Toward Open Co-Scientists (li…huan sun, 2025) - 5k scientific coding tasks automatically scraped from github repos for papers (as a sanity check, they manually verified that a subset were reasonable)
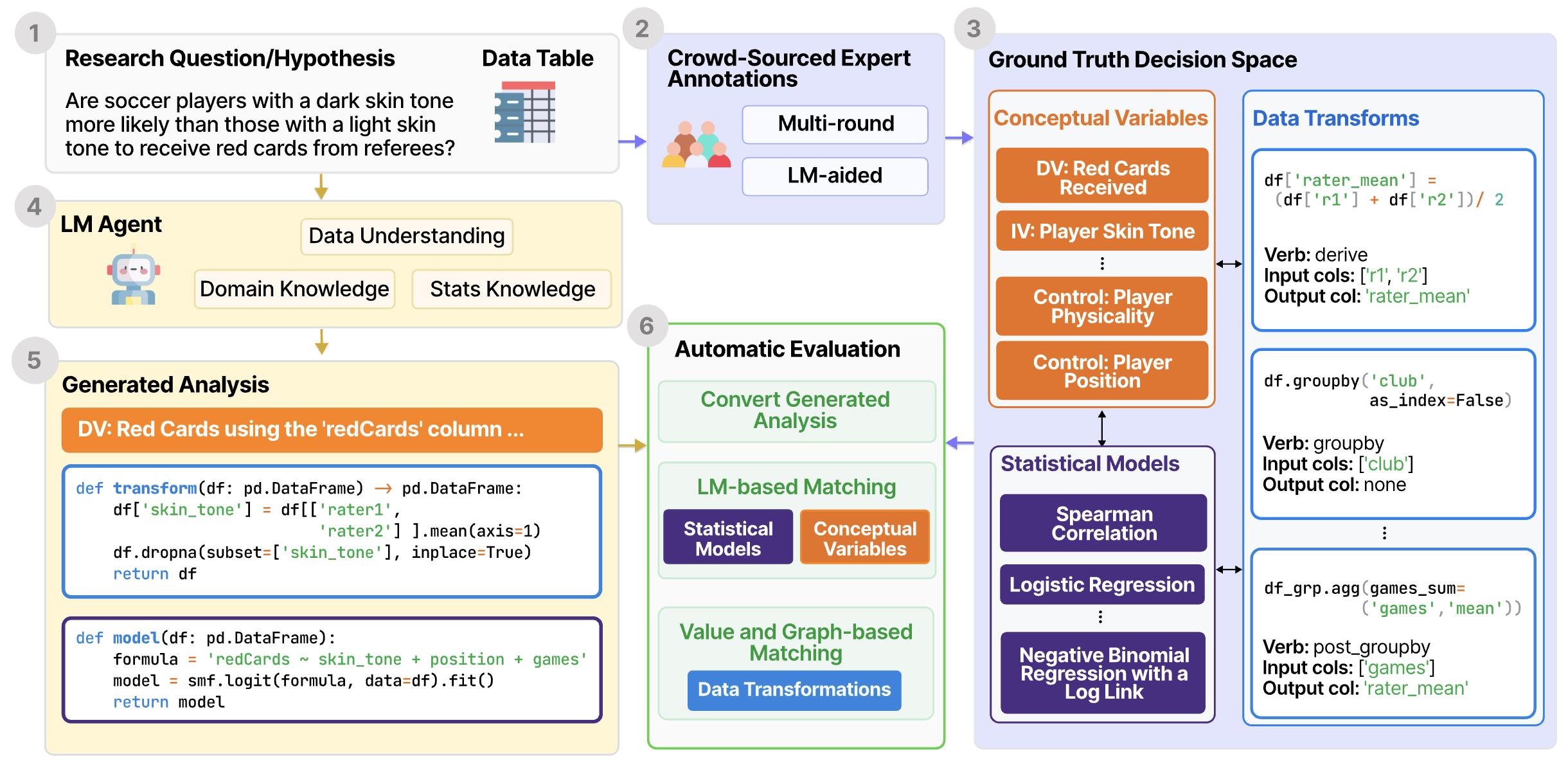
DiscoveryBench: Towards Data-Driven Discovery with Large Language Models (majumder…clark, 2024) - 264 tasks collected across 6 diverse domains, such as sociology and engineering, by manually deriving discovery workflows from papers
- each task has datasets, metadata, natural-language discovery goal

BLADE: Benchmarking Language Model Agents for Data-Driven Science (gu…althoff, 2024) - 12 tasks, each has a (fairly open-ended) research question, dataset, and groundtruth expert-conducted analysis
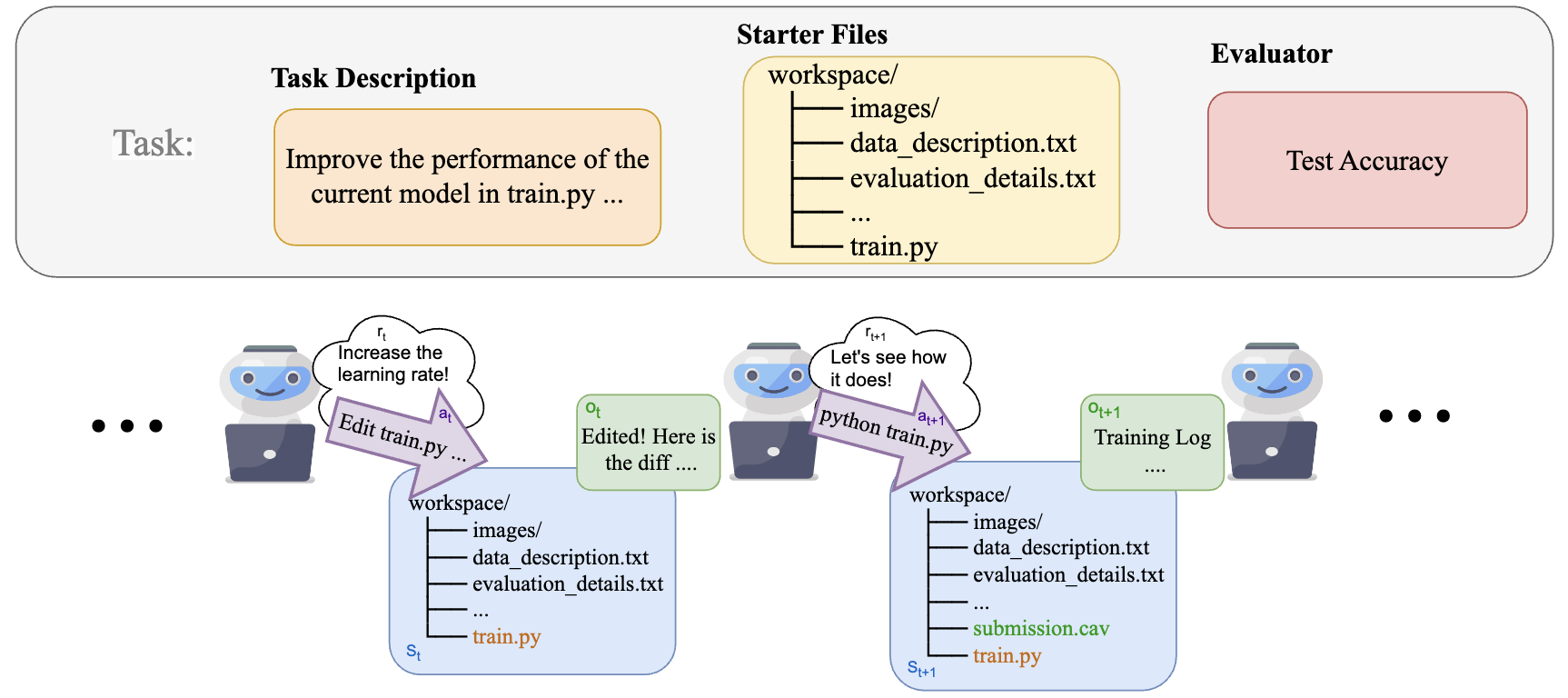
Mlagentbench: Benchmarking LLMs As AI Research Agents (huang, vora, liang, & leskovec, 2023) - 13 prediction tasks, e.g. CIFAR-10, BabyLM, kaggle (evaluate via test prediction perf.)
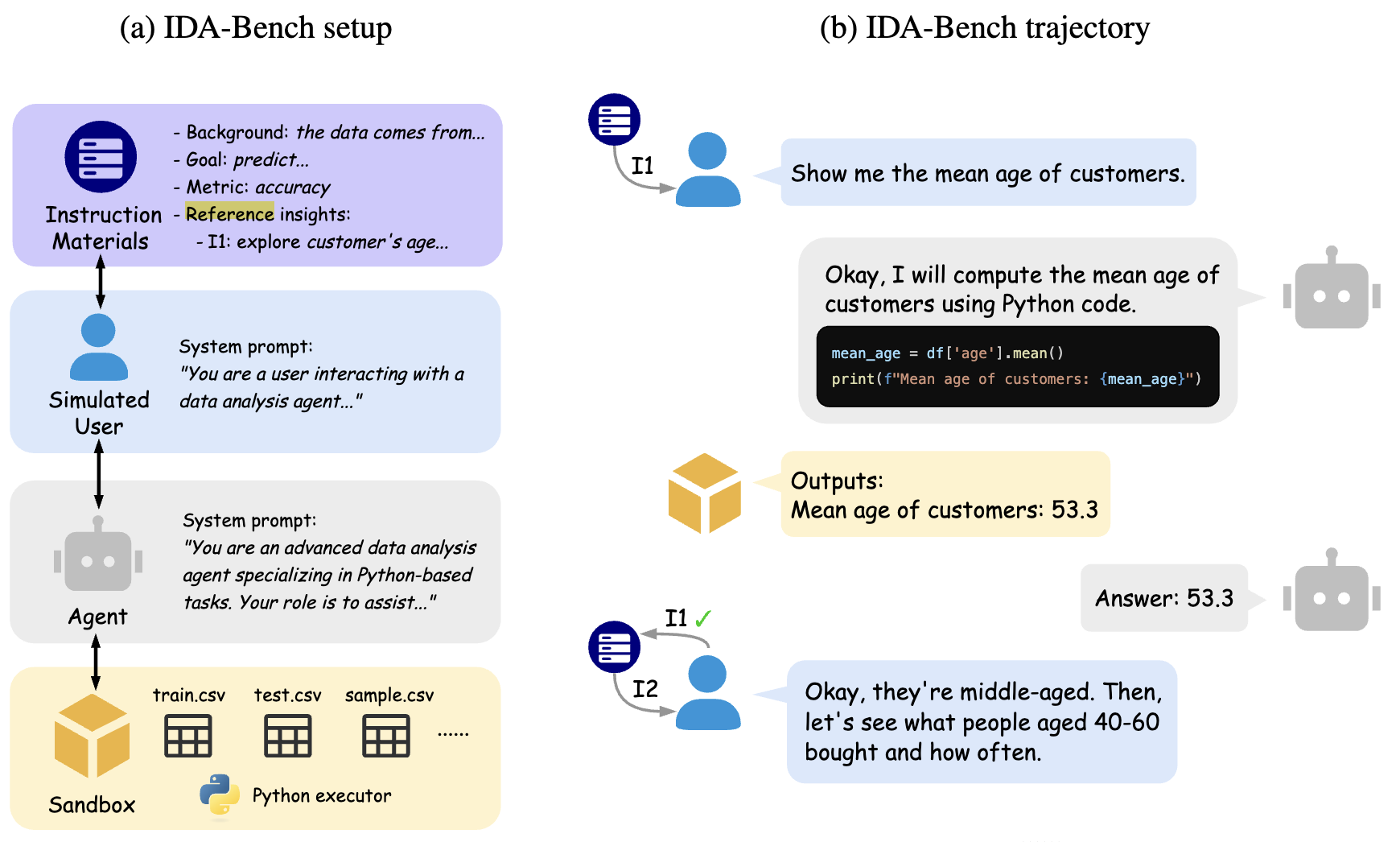
IDA-Bench: Evaluating LLMs on Interactive Guided Data Analysis (li…jordan, 2025) - scraped 25 notebooks from recent kaggle competitions, parse into goal + reference insights that incorporate domain knowledge
- paper emphasizes interactive setting: evaluates by using the instruction materials to build a knowledgeable user simulator and then tests data science agents’ ability to help the user simulator improve predictive performance
InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks (hu…wu, 2024) - 257 precise (relatively easy) questions that can be answered from 1 of 52 csv datasets