| '26 |
Agentic-imodels: evolving agentic interpretability tools via autoresearch
|
Singh, Tan, Xu, Gero, Yang, Galley, & Gao |
🔎🌀 |
arXiv |
|
|
| '26 |
Generative causal testing
|
Antonello*, Singh*, Jain, Hsu, Gao, Yu, & Huth |
🧠🔎🌀 |
Nature Neuroscience |
|
|
| '26 |
Sanity checks for agentic data science
|
Rewolinski*, Zane*, Huang, Singh, Wang, Gao, & Yu |
🔎🌀 |
arXiv |
|
|
| '26 |
Test-time learning with an evolving library
|
Xu, Sordoni, Singh, Gero, Galley, Yuan, & Gao |
🌀 |
arXiv |
|
|
| '26 |
Test-time recursive thinking
|
Zhuang, Singh, Liu, Shen, Zhang, Shang, Gao, & Chen |
🌀 |
arXiv |
|
|
| '26 |
Selecting feature interactions by distilling foundation models
|
Jia, Singh, Carauana, & Lengerich |
🔎🌀 |
arXiv |
|
|
| '26 |
Human-AI co-design for clinical prediction models
|
Feng*, Kothari*, Vossler, Bishara, Zier, Addo, Kornblith, Tan, & Singh |
💊🌀 |
npj Digital Medicine |
|
|
| '26 |
Do explanations generalize across large reasoning models?
|
Pal, Bau, & Singh |
💊🌀 |
arXiv |
|
|
| '26 |
Data-efficient adaptation of LLMs via attention head reweighting
|
Oikarinen, Chen, Siska, Weng, Singh, & Gao |
🌀🔎 |
COLM |
|
|
| '26 |
Interpreting and steering state-space models via activation subspace bottlenecks
|
Mohan, Gupta, Das, & Singh |
🔎🌀 |
ICML |
|
|
| '25 |
Evaluating scientific theories as predictive models in language neuroscience
|
Singh*, Antonello*, Guo, Mischler, Gao, Mesgarani, & Huth |
🧠🔎🌀 |
bioRxiv |
|
|
| '25 |
Mixture of inputs |
Zhuang, Liu, Singh, Shang, & Gao |
🌀 |
NeurIPS |
|
|
| '25 |
Interpretable language modeling via induction-head ngram models
|
Kim*, Mantena*, Yang, Singh, Yoon, & Gao |
🧠🔎🌀 |
NeurIPS |
|
|
| '25 |
Bayesian concept bottleneck models with LLM priors
|
Feng, Kothari, Zier, Singh, & Tan |
🔎🌀 |
NeurIPS |
|
|
| '25 |
OmniGuard |
Verma, Hines, Bilmes, Siska, Zettlemoyer, Gonen, & Singh |
🌀 |
EMNLP |
|
|
| '25 |
Systematic bias in clinical decision instrument development
|
Obra, Singh, et al. |
🔎💊 |
npj Digital
Medicine |
|
|
| '25 |
Analyzing patient perspectives with LLMs
|
Kornblith*, Singh* et al. |
💊🌀 |
Nature Scientific
Reports |
|
|
| '25 |
SimDINO
|
Wu et al. |
🌀 |
ICML |
|
|
| '25 |
Vector-ICL: in-context learning with continuous vector representations
|
Zhuang et al. |
🔎🌀 |
ICLR |
|
|
| '24 |
Crafting interpretable embeddings by asking LLMs questions
|
Benara*, Singh*, Morris, Antonello, Stoica, Huth, & Gao |
🧠🔎🌀 |
NeurIPS |
|
|
| '25 |
Towards understanding graphical perception in large multimodal models
|
Zhang et al. |
🌀 |
arXiv |
|
|
| '24 |
Rethinking interpretability in the era of large language models
|
Singh, Inala, Galley, Caruana, & Gao |
🔎🌀 |
arXiv |
|
|
| '24 |
Towards consistent natural-language explanations via explanation-consistency finetuning
|
Chen et al. |
🔎🌀 |
COLING |
|
|
| '24 |
Learning a decision tree algorithm with Transformers
|
Zhuang et al. |
🔎🌀🌳 |
TMLR |
|
|
| '24 |
Model tells itself where to attend: faithfulness meets automatic attention steering
|
Zhang*, Yu*, et al. |
🔎🌀 |
arXiv |
|
|
| '24 |
Tell your model where to attend: post-hoc attention steering for LLMs
|
Zhang et al. |
🔎🌀 |
ICLR |
|
|
| '24 |
Attribute structuring improves LLM-based evaluation of clinical text summaries
|
Gero et al. |
🔎🌀 |
ML4H findings |
|
|
| '23 |
Tree prompting
|
Morris*, Singh*, Rush, Gao, & Deng |
🔎🌀🌳 |
EMNLP |
|
|
| '23 |
Augmenting interpretable models with LLMs during training
|
Singh, Askari, Caruana, & Gao |
🔎🌀🌳 |
Nature Communications |
|
|
| '23 |
Explaining black box text modules in natural language with language models
|
Singh*, Hsu*, Antonello, Jain, Huth, Yu & Gao |
🔎🌀 |
NeurIPS workshop |
|
|
| '23 |
Self-verification improves few-shot clinical information extraction
|
Gero*, Singh*, Cheng, Naumann, Galley, Gao, & Poon |
🔎🌀💊 |
ICML workshop |
|
|
| '22 |
Explaining patterns in data with language models via interpretable autoprompting
|
Singh*, Morris*, Aneja, Rush, & Gao |
🔎🌀 |
EMNLP workshop |
|
|
| '22 |
Stress testing a clinical decision instrument performance for intra-abdominal injury
|
Kornblith*, Singh* et al. |
🔎🌳💊 |
PLOS Digital
Health |
|
|
| '22 |
Fast interpretable greedy-tree sums (FIGS) |
Tan*, Singh*, Nasseri, Agarwal, & Yu |
🔎🌳 |
PNAS |
|
|
| '22 |
Hierarchical shrinkage for trees |
Agarwal*, Tan*, Ronen, Singh, & Yu |
🔎🌳 |
ICML (spotlight) |
|
|
| '22 |
VeridicalFlow: a python package for building trustworthy data science pipelines with PCS |
Duncan*, Kapoor*, Agarwal*, Singh*, & Yu |
💻🔍 |
JOSS |
|
|
| '21 |
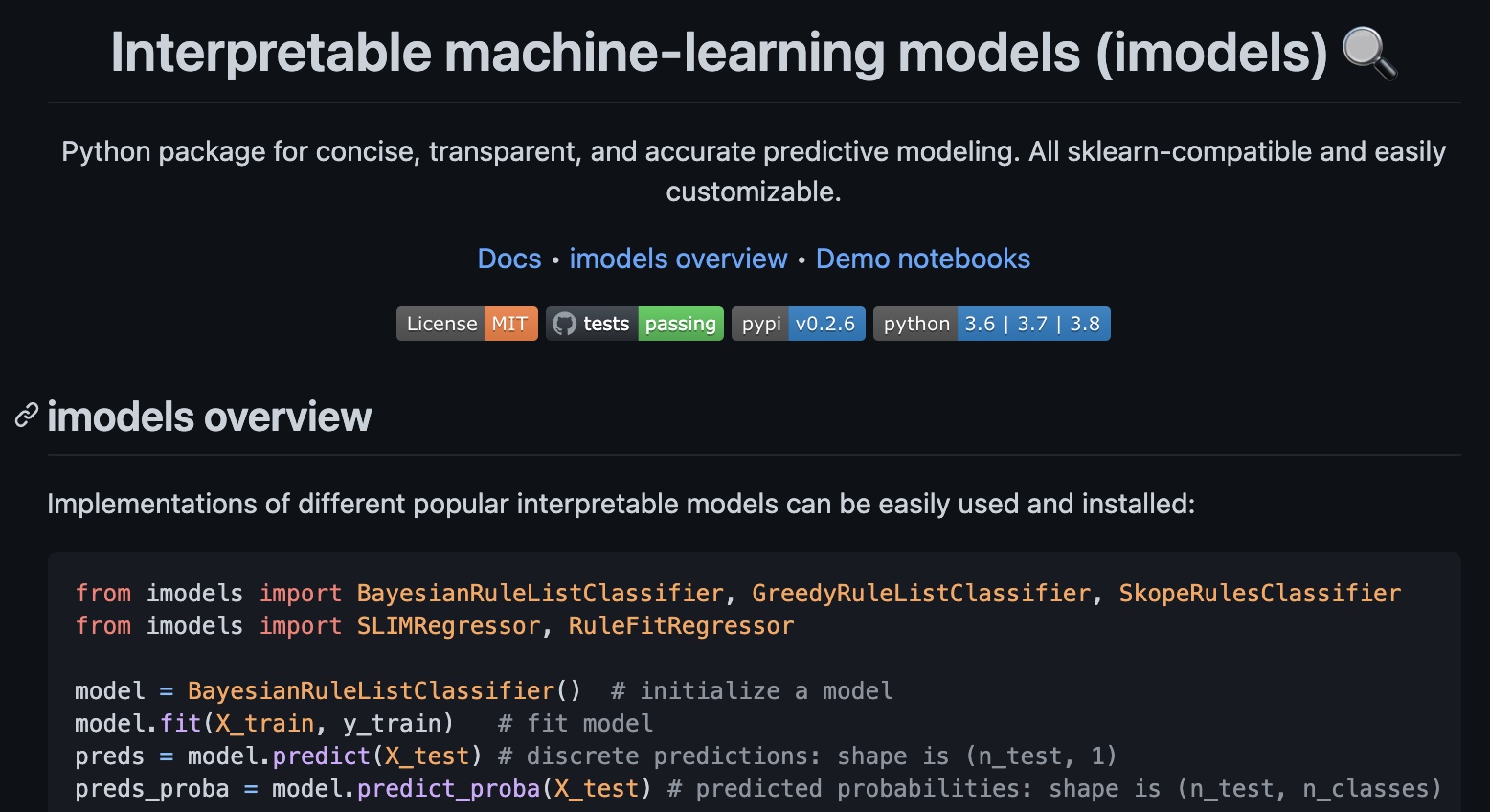
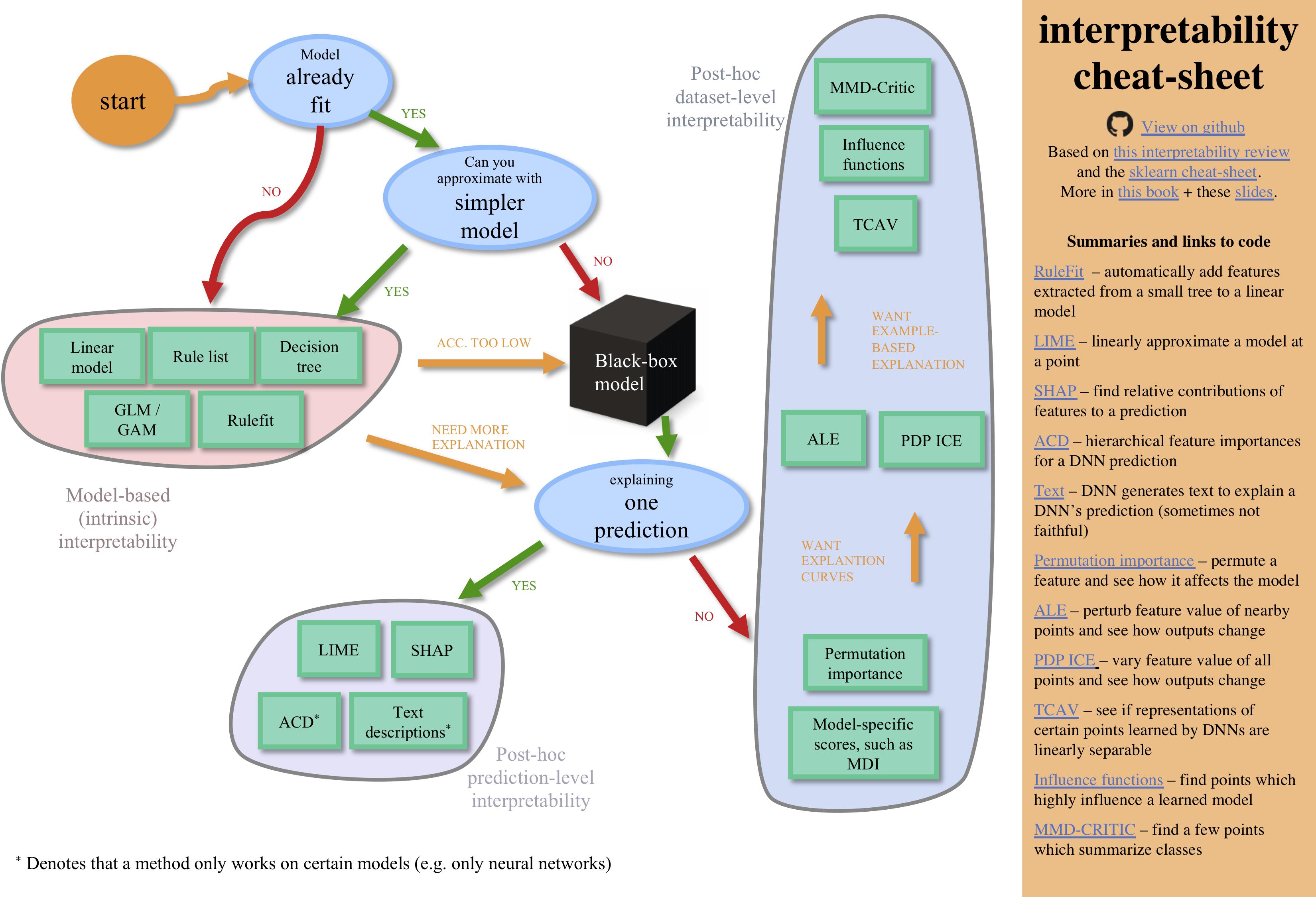
imodels: a python package for fitting interpretable models |
Singh*, Nasseri*, et al. |
💻🔍🌳 |
JOSS |
|
|
| '21 |
Adaptive wavelet distillation from neural networks through interpretations |
Ha, Singh, et al. |
🔍🌀🌳 |
NeurIPS |
|
|
| '21 |
Matched sample selection with GANs for mitigating attribute confounding |
Singh, Balakrishnan, & Perona |
🌀 |
CVPR workshop |
|
|
| '21 |
Revisiting complexity and the bias-variance tradeoff |
Dwivedi*, Singh*, Yu & Wainwright |
🌀 |
JMLR |
|
|
| '20 |
Curating a COVID-19 data repository and forecasting county-level death counts in the United States |
Altieri et al. |
🔎🦠 |
HDSR |
|
|
| '20 |
Transformation importance with applications to cosmology |
Singh*, Ha*, Lanusse, Boehm, Liu & Yu |
🔎🌀🌌 |
ICLR workshop (spotlight) |
|
|
| '20 |
Interpretations are useful: penalizing explanations to align neural networks with prior knowledge |
Rieger, Singh, Murdoch & Yu |
🔎🌀 |
ICML
|
|
|
| '19 |
Hierarchical interpretations for neural network predictions |
Singh*, Murdoch*, & Yu |
🔍🌀 |
ICLR |
|
|
| '19 |
Interpretable machine learning: definitions, methods, and applications |
Murdoch*, Singh*, et al. |
🔍🌳🌀 |
PNAS |
|
|
| '19 |
Disentangled attribution curves for interpreting random forests and boosted trees |
Devlin, Singh, Murdoch & Yu |
🔍🌳 |
arXiv |
|
|
| '18 |
Large scale image segmentation with structured loss based deep learning for connectome reconstruction
|
Funke*, Tschopp*, et al. |
🧠🌀 |
TPAMI |
|
|
| '18 |
Linearization of excitatory synaptic integration at no extra cost |
Morel, Singh, & Levy |
🧠 |
J Comp Neuro |
|
|
| '17 |
A consensus layer V pyramidal neuron can sustain interpulse-interval coding |
Singh & Levy |
🧠 |
PLOS
One |
|
|
| '17 |
A constrained, weighted-l1 minimization approach for joint discovery of heterogeneous neural
connectivity
graphs
|
Singh, Wang, & Qi |
🧠 |
NeurIPS Workshop |
|
|