transformers
Contents
1.9. transformers#
1.9.1. papers#
See related papers in the 📌 interpretability page.
1.9.1.1. high-performing#
nlp (see also this link)
early papers
attention is all you need (vaswani et al. 2017) - initial transformer
encoder-decoder transformer for seq-to-seq (most new models don’t have special encoder-decoder structure for translation)
Semi-supervised Sequence Learning (dai & quoc le, 2015)
context vector is weighted sum of context vector at each word
ULMFiT (howard & ruder, 2018)
BERT (devlin et al. 2018) - semi-supervised learning (predict masked word - this is bidirectional) + supervised finetuning
roberta (liu et al. 2019)
BART (lewis et al. 2019) - generalizes BERT with sequence-to-squence training: train by (1) corrupting text then (2) reconstruct the original text
ELMo (peters…zettlemoyer, 2018) - no word embeddings - train embeddings w/ bidirectional lstm (on language modeling)
XLNet (yang…quoc le, 2020)
GPT-4 (openai, 2023) - adds multimodal understanding + boosts context length to 32k
GPT-3 (brown et al. 2020) - identitical to GPT-2 except larger and replaces dense attention with sparse attention
sizes: largest has 175B params, 96 layers, 96 heads in each layer, head with dim 128, vocab size ~50k
InstructGPT (ouyang…lowe, 2022)
GPT-2 (radford et al. 2018)
GPT (radford et al. 2018)
Gopher (deepmind, 2021) - basically gpt-3 with slight mods (replace layernorm by RMSnorm, different positional embeddings)
open-source (from meta ai): LlaMa 2, LLaMa, OPT-IML, OPT
GPT4All (LLaMA 7B finetuned on code/stories/dialogue)
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (clark…quoc le, chris manning, 2020)
more efficient: rather than standard masked training, use generator-discriminator setup for “token detection”
generator replaces many masked tokens with plausible samples - train with MLM
discriminator tries to guess which tokens were the masked ones - this is the main model that gets used
LongNet: Scaling Transformers to 1,000,000,000 Tokens (ding, …, wei, 2023) - multiscale attention similar to wavelets
Longformer: The Long-Document Transformer (Beltagy, Peters, & Cohan 2020) - processes very long contexts
Lost in the Middle: How Language Models Use Long Contexts (liu…petroni, liang, 2023)
PaLM: Scaling Language Modeling with Pathways (Google 2022) - 540 Billion params
pathways hardware center allows for fast/efficient training
discontinuous improvements - at some point large model improves
prompt engineering: “Explain yourself” - lets it explain jokes
Chinchilla: Training Compute-Optimal Large Language Models (DeepMind 2022)
“chinchilla scaling laws” - for compute-optimal training, the model size and the number of training tokens should be scaled equally
T0 (sanh…rush, 2022) - multitask training enables better zero-shot generalization
T5 (raffel…liu, 2020) – text-to-text transfer transformer
UL2: Unifying Language Learning Paradigms (tay…metzler, 2022) - open-source 20B model, beats GPT-3 at zero-shot
more effective training
instruction following
FLAN-PaLM: Scaling Instruction-Finetuned Language Models (chung, …, quoc le, jason wei, 2022) - finetune with datasets phrased as instructions
FLAN (wei, …, le, 2021) - finetune on instructions to follows instructions
human feedback
Learning to summarize with human feedback (OpenAI, 2020)
Can language models learn from explanations in context? (lampinen et al. 2022)
natural language feedback (scheurer et al. 2022) - makes training more efficient
Training Language Models with Language Feedback at Scale (scheurer et al. 2023)
Explanation-based Finetuning Makes Models More Robust to Spurious Cues (ludan…callison-burch, 2023)
Post hoc explanations of language models can improve language models (krishna…singh, lakkaraju, 2023) - use rationales as corrective signals for LLMs
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback (lee…rastogi, 2023)
other
text-vision models
CLIP (radford et al. 2021) - jointly train text/images
batch-based loss: encodings from same image/text pair should be close while encodings across different examples in the batch should be different
note: empirically works better with very large batch size
DALL-E 2 (OpenAI, 2022)
clip is foundation as generative model
generates text + image embeddings
“prior network” maps text embedding to image embedding
adds diffusion model
Stable diffusion (stability.ai, 2022) - open-source recreation, now highly optimized for speed
Imagen (google, 2022)
BLIP-2 (salesforce, 2023) - Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
BEiT-3 (2022) - treat vision as language and large-scale multimodal training
outperforms Flamingo: a Visual Language Model for Few-Shot Learning (2022), which uses more domain knowledge to connect vision & language
video
Text-To-4D Dynamic Scene Generation (meta, 2023)
vision
VIT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (dosoviskiy, …, houlsby, 2020)
attention augmentation to resnet for vision (bello…quoc le, 2020)
here, people call image patches “tokens”
DINO Emerging Properties in Self-Supervised Vision Transformers (caron…joulin, 2021)
Masked Autoencoders Are Scalable Vision Learners (he…dollar, girshick, 2021) - BERT-style training
speed up by not applying encoder to mask tokens + adding mask to a lot of the data (like 75%)
really good results without much data
spatial transformers networks (deepmind, 2015)
rl
AdA: Human-Timescale Adaptation in an Open-Ended Task Space (deepmind, 2023)
GATO: A Generalist Agent (deepmind, 2022) - single agent plays many different video games
different modalities are converted to tokens differently (e.g. image patches are fed through resnet)
In-context Reinforcement Learning with Algorithm Distillation (laskin, wang, …, sahni, satinder singh, mnih, 2022, deepmind) - learn to improve an RL algorithm
put history of (observation, action, reward) sequences into context and then use them to predict new action given new observation
Decision Transformer: Reinforcement Learning via Sequence Modeling (chen, lu, …abbeel, srinivas, mordatch, 2021) - transformer that predicts what the next highest reward step is instead of the next word
question-answering (now just done with generic LLMs)
UnifiedQA: Crossing Format Boundaries With a Single QA System (khashabi…hajishirzi, 2020)
dialog
ChatGPT
GODEL: Large-Scale Pre-Training for Goal-Directed Dialog (baolin peng, galley, …, gao , 2022) - add grounded pre-training
Deal or No Deal? End-to-End Learning for Negotiation Dialogues (lewis…batra, 2017, Meta) - controversial paper where agents “make up their own language”
this is pre-transformers
MINERVA: Solving Quantitative Reasoning Problems with Language Models (google, 2022) - train on well-parsed, domain-specific data (math arxiv) to solve math-reasoning problems
autoformalization (wu…, szegedy, 2022) - translating from natural language math to formal language
produce sql/python that then finds an answer (cheng…zettlemoyer, smith, yu, 2022)
CODEX: Evaluating Large Language Models Trained on Code (2021, openai)
Repair Is Nearly Generation: Multilingual Program Repair with LLMs (Joshi et al. 2022)
Improving automatically generated code from Codex via Automated Program Repair (Fan et al. 2022) - use automated program repair to tweak codex outputs to make them better
Generating Question Titles for Stack Overflow from Mined Code Snippets (Gao et al. 2020)
Automatic Program Repair with OpenAI’s Codex: Evaluating QuixBugs (Prenner & Robbes, 2021)
use prompt like:
#### fix the bug in the following function <buggy function and/or docstring here> #### fixed function
program synthesis arxiv.org/abs/2108.07732 - formalize natural language into runnable code
science
Galactica: A Large Language Model for Science (taylor…, stojnic, 2022, meta ai) - trained on mostly papers + some knowledge bases (e.g. proteins)
Nougat: Neural Optical Understanding for Academic Documents (blecher…scialom, sojnic, 2023)
music
MusicLM: Generating Music From Text (google, 2023)
Jukebox: A Generative Model for Music (openai, 2020)
summarization / keywords
KeyBERT: Minimal keyword extraction with BERT (grootendorst, 2020)
text-to-speech
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale (meta, 2023)
1.9.1.2. external knowledge / tool use / grounding#
private
https://www.perplexity.ai/ - nice demo adding citation to each fact
langchain library
https://www.fixie.ai/ - provide tools for wrapping APIs in LLM + interaction through router (also default modules for stateful storage, user identity, etc.)
review
Augmented Language Models: a Survey (meta, 2023) – 3 categories: reasoning, tools, action
Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP (khattab, …, liang, potts, & zaharia, 2022) - use high-level programs to use multiple steps between retrieving and reading
Toolformer: Language Models Can Teach Themselves to Use Tools (meta, 2023) - model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction
Given input, sample position and API call candidates, try them all, and filter out ones which do not reduce next-token loss
put correct API calls into prompt, e.g. Pittsburgh is also known as
[QA(What ...?→ Steel City)]the Steel City.
Training
start with few human-written examples of API use
LLM generates more uses
self-supervised loss determines which calls help with future-token prediction
Atlas: Few-shot Learning with Retrieval Augmented Language Models (meta, 2022)
retreival-augmented in-context learning (put retrieved info into context, or something very similar)
REALM (guu, …, chang, 2020) - retrieves document chunks from corpus and adds them to context, for open-domain QA
RETRO (deepmind, 2022) - nearest neighbors to model’s input are retrieved, encoded, and conditioned on with chunked cross-attention
Decomposed prompting (khot et al., 2022) - decompose tasks via prompting which are delegated to a shared library of prompting-based LLMs dedicated to these sub-tasks
LLM-Augmenter (peng, galley…gao, 2023) - (1) consolidates evidence from external knowledge for the LLM to generate responses grounded in evidence, and (2) revising LLM’s (candidate) responses using automated feedback
knowledge base triplets
Relational Memory-Augmented Language Models (liu, yogatama, & blunsom, 2022) - integrate knowledge base triplets with LLM
DRAGON: Deep Bidirectional Language-Knowledge Graph Pretraining (yasanaga, …, manning, liang, leskovec, 2022)
webgpt (nakano, …, schulman, 2022, OpenAI) - allows google search to add world info
Internet-augmented language models Lazaridou et al., 2022
GopherCite (menick, …, mcaleese, 2022, Deepmind) - generate answers + link/relevant snippet when making predictions (trained with RL from human preferences )
LaMDA (thoppilan, …, quoc le, 2022, google) - allows google search to add world info (in a dialog model)
this was the model that sparked the controversy about consciousness 🤔
A Neural Corpus Indexer for Document Retrieval (wang…yang, 2022) - train model to directly spit out document IDs given queries
RLPG (shrivastava, larochelle, & tarlow, 2022) - for code-completion, retrieves functions from a repo
memorizing transformers (wu…szegedy, 2022) - knn-based learned indexing + retrieval at training time
at test time, you just need to index the entire context and the model will be able to use it
kNN Prompting: Learning Beyond the Context with Nearest Neighbor Inference (xu…zhang, 2023) - instead of verbalizer, use nearest-neighbor
has dbpedia results
kNN-Prompt: Nearest Neighbor Zero-Shot Inference (shi…zettlemoyer, 2022)
self-verification
Self-Refine: Iterative Refinement with Self-Feedback (madaan, …, clark, 2023)
Self-Verification Improves Few-Shot Clinical Information Extraction (gero et al. 2023)
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models (manakul…gales, 2023)
ACT-1: Transformer for Actions (2022, Adept) - transformer directly interacts with computer
ReAct: Synergizing Reasoning and Acting in Language Models (yao…cao, 2022) - use LLMs to generate reasoning traces + task-specific actions in interleaved manner
1.9.2. prompting#
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing (liu…neubig, 2021)
from feature-engineering -> architecture engineering -> prompt engineering
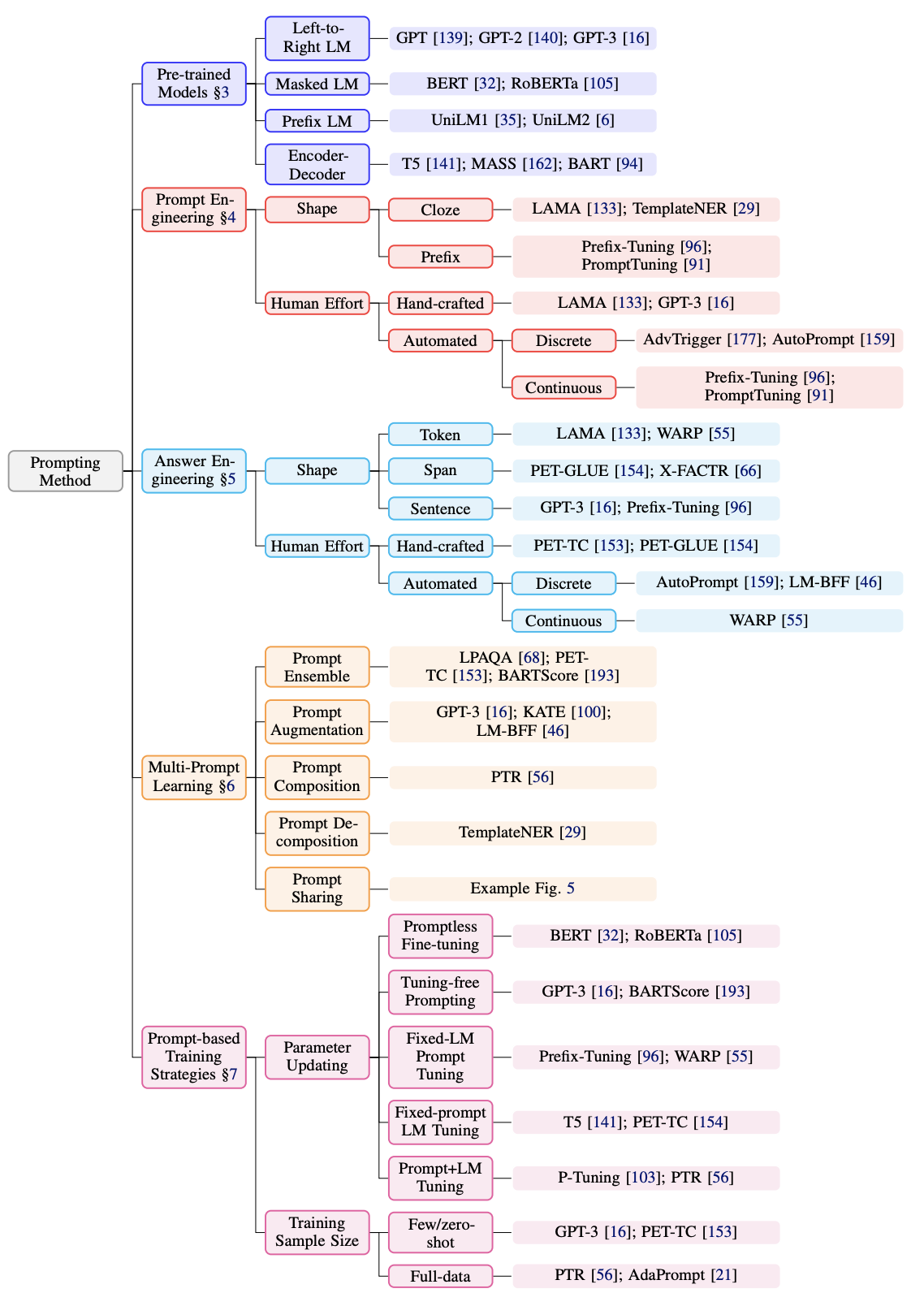
LAMA Language Models as Knowledge Bases? (petroni…riedel, 2019) - Proposes using fill-in-the-blank (cloze) prompts for extracting knowledge from large language models
create LAMA probe - dataset of (subject, relation, object) triplets with templates – find that BERT can recall these relations
How to Query Language Models? (adolphs et al. 2021) - query LLMs by example (e.g. “Ronaldo plays for Portugal. Who does Neuer play for?”)
How Can We Know What Language Models Know? (jiang … neubig, 2020)
mining-based and paraphrasing-based methods to automatically generate high-quality diverse prompts
ensemble methods to combine answers from different prompts (e.g. avg logits and more)
Noisy Channel Language Model Prompting for Few-Shot Text Classification (min et al. 2022)
Querying \(P(question|answer)\) with Bayes rule outperforms standard querying \(P(answer|question)\)
memory-assisted prompt-editing (madaan…yang, 2022) - allows model to “save things to memory” that get added to prompt when needed
Prompting Is Programming: A Query Language For Large Language Models (Beurer-Kellner, Fischer, & Vechev, 2022)
1.9.2.1. (auto)prompting#
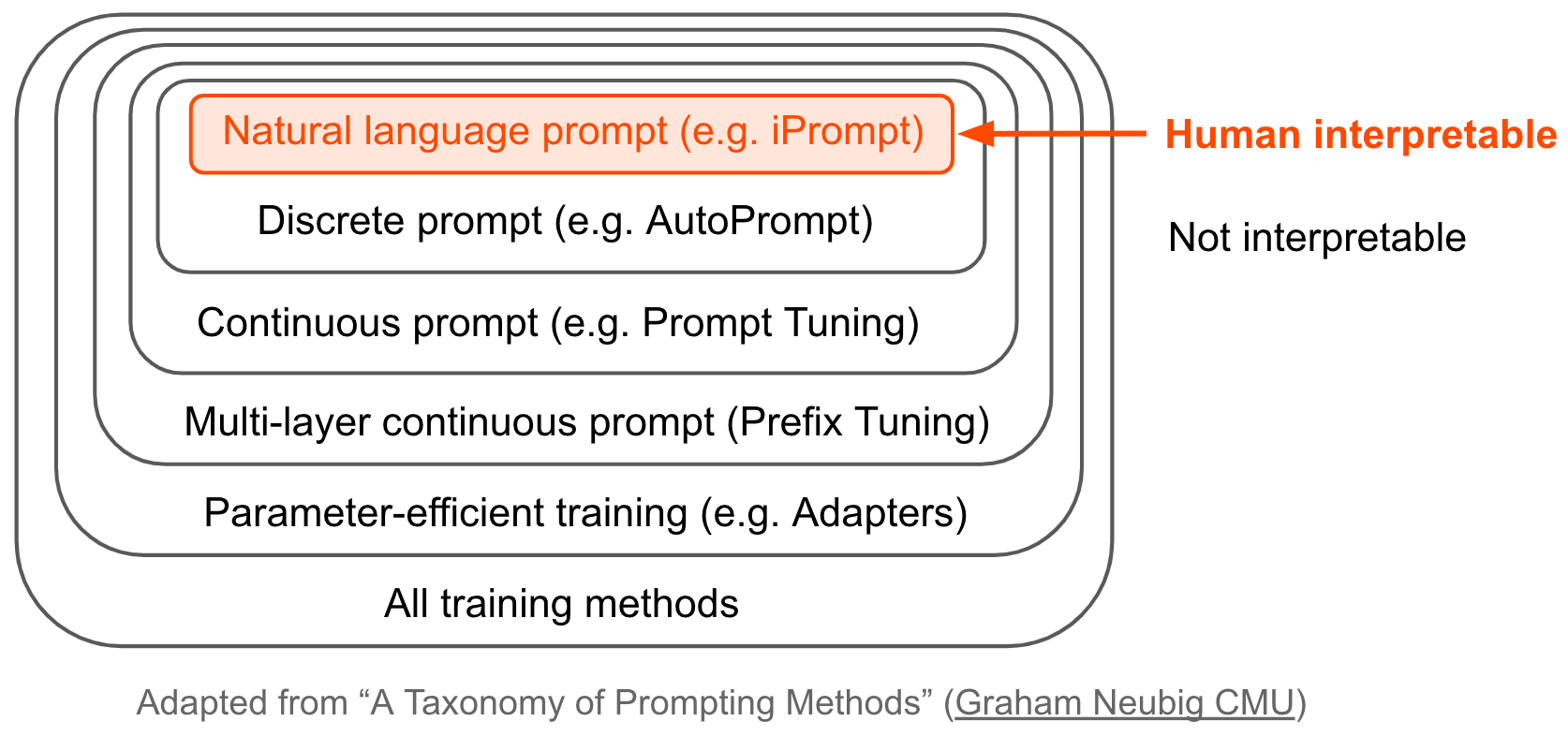
natural-language prompting
iPrompt: Explaining Patterns in Data with Language Models via Interpretable Autoprompting (singh, morris, …gao, 2022)
APE: Large Language Models Are Human-Level Prompt Engineers (zhou…ba, 2022)
similar to iPrompt, (1) propose prompt candidates with an LLM, (2) score the prompts by the accuracy they yield when using another LLM and (3) regenerate similar prompt candidates
experiments on instruction induction datasets + truthful QA
FluentPrompt: Toward Human Readable Prompt Tuning (shi, …, zettlemoyer, 2022) - use langevin sampling + fluency constraint to generate prompt
experiments relatively weak: 3 sentiment datasets + autoprompt is the only baseline
APO: Automatic Prompt Optimization with “Gradient Descent” and Beam Search (pryzant…zeng, 2023) - update prompts based on errors made by previous prompts
OPRO: Large Language Models as Optimizers (yang…quoc le, zhou, & chen , 2023) - add in past prompts with their scores during optimization
Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers (guo…yang, 2023)
Language Models as Black-Box Optimizers for Vision-Language Models (yu…pathak, & ramanan, 2023)
discrete prompting
AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts (shin…sameer singh, 2020)
select prompts from a fixed set of tokens (resulting prompts are not coherent)
only work on MLM
elicit sentiment / factual knowledge
Universal Adversarial Triggers for Attacking and Analyzing NLP (wallace…sameer singh, 2019) - find input-agnostic sequences of tokens that trigger a model to produce a specific prediction when concatenated to any input from a dataset
RLPrompt: Optimizing Discrete Text Prompts with Reinforcement Learning (deng…hu, 2022)
LM-BFF: Making Pre-trained Language Models Better Few-shot Learners (gao et al. 2020) - uses T5 to generate (i) template for the task (which might include a whole example or two) + (i) appropropriate label tokens in the vocabulary for the task (suffers from computationally intensive search + sub-optimal discrete space search)
PADA: Example-based Prompt Learning for on-the-fly Adaptation to Unseen Domains (ben-david, …, reichart, 2022)
prompt ensembles
PromptBoosting: Black-Box Text Classification with Ten Forward Passes (hou, …, jacob andreas, …, zhang, 2022) - get a small pool of prompts, learn a verbalizer (final classification layer) for each, then ensemble them with AdaBoost on LLM output
people have studied many works on prompt ensembling (e.g. lester et al. 2021)
PRBOOST: Prompt-Based Rule Discovery and Boosting for Interactive Weakly-Supervised Learning (zhang…zhang, 2022) - iteratively (1) select high-error examples, (2) have human label them as rules, and (3) use boosting to train model on the new rules + ensemble
typical rule generation
Snuba (Varma and Ré, 2018) generates heuristics based on a small labeled dataset with pre-defined rule types
TALLOR (Li et al. 2021a) & GLaRA (Zhao et al. 2021) study rule expansion for NER problem based on lexical information and then select rules based on a hand-tuned threshold
PTR: Prompt Tuning with Rules for Text Classification (han et al. 2021) – use logic rules to construct prompts with sub-prompts for many-class text classification (prompt is constructed hierarchically, but only one call is made to the LLM for inference)
Prefix-Tuning: Optimizing Continuous Prompts for Generation (li & percy liang, 2021) – optimizes in continuous space for language generation tasks
learn to map some parameters \(\theta\) through and MLP to generate a starting hidden state \(h_i\) – never actually sends the prefix through the network
Control Prefixes for Parameter-Efficient Text Generation (clive, cao, & rei, 2022) - allow for adapting the prefix to each input example
DART Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners (zhang…chen, 2022)
reformulating NLP task into differentially optimizing the prompt template + target label (given a pre-trained model)
focus on smaller models (Roberta-large + GPT-2) + few training shots
fluency constraint to ensure association among prompt embeddings
P-Tuning – GPT Understands, Too (liu et al. 2021) – use LSTM to generate prompt embeddings (don’t map to tokens)
Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification (Hu et al. 2021) – add knowledge-base info into the prompt search
Learning How to Ask: Querying LMs with Mixtures of Soft Prompts (Qin & Eisner, 2021)
use continuous tokens and ensemble (don’t map back to words)
WARP: Word-level Adversarial ReProgramming (Hambardzumyan et al. 2021) - add continous tokens (don’t map back to words) + some task-specific parameters for better generalization
KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction (Chen et al. 2021) – incorporate relations, visualize learned prompt vectors with t-SNE
Calibrate Before Use: Improving Few-Shot Performance of Language Models (zhao, …, dan klein, sameer singh, 2021) - in order to make prompting easier, first calibrate output distr by making it uniform when given null inputs, e.g. “N/A”
misc
SentiPrompt: Sentiment Knowledge Enhanced Prompt-Tuning for Aspect-Based Sentiment Analysis (Zhang et al. 2021) – use sentiment knowledge penalties in the prompt
Meta-learning via Language Model In-context Tuning (Chen et al. 2022) – Given new task with new instruction
Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm (Reynolds & McDonell, 2021) – define metaprompts as general wrappers around tasks e.g. “This problem asks us to”
Re3: Generating Longer Stories With Recursive Reprompting and Revision (Yang et al. 2022) - generate summaries, then expand and revise with prompts
Directional Stimulus Prompting (li, baoling peng, …jianfeng gao, xifeng yan, 2023) - generate hint keywords using small LLM that are put into the prompt when calling large LLM
critiques of prompting
Do Prompt-Based Models Really Understand the Meaning of their Prompts? (webson & pavlick, 2022) - models can learn fine with prompts that are intentionally irrelevant
Are Language Models Worse than Humans at Following Prompts? It’s Complicated (webson, …, pavlick, 2023)
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity (lu…riedel, stenetorp, 2021)
can benefit from training for promptability
Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections (zhong…klein, 2021)
Continued Pretraining for Better Zero- and Few-Shot Promptability (wu…sameer singh, beltagy, 2022)
Context-faithful Prompting for Large Language Models (zhou, shang, poon & chen, 2023) - ask question in clever way to force LLM to follow it
1.9.2.2. llm chaining / decoding#
many notes are from this thread on chaining models together
steering
overviews
Ai chains: Transparent and controllable human-ai interaction by chaining large language model prompts (wu, terry, & cai, 2022) - chaining LLM steps together: output of one step becomes the input for the next
interactive system where users can modify chains + their intermediate results – improves performance + human experience
Language Model Cascades (dohan…sutton, 2022) - treat chaining models as probabilistic programs
use a probabilistic-programming language (PPL) to define a joint probability model on string-valued random variables, parameterized using LMs, and then condition this model on string-valued observations in order to compute a posterior over string-valued unknowns
self-PPLs extend probabilistic graphical models to support more complex joint distributions whose size and “shape” can itself be stochastic
e.g., a graph unrolled for a random number of iterations, until a data-dependent stopping criterion is met
variables are all text: questions \(Q\), answers \(A\), and intermediate thoughts \(T\)
posthoc
2023
Faithful Chain-of-Thought Reasoning (lyu et al. 2023)
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks (chen et al. 2022)
PAL: Program-aided Language Models (gao…neubig, 2023)
Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting (turpin, …, bowman, 2023)
CoT explanations can be heavily influenced by biasing the model towards certain answers, thereby yielding invalid explanations
try biasing in 2 ways: answer is always (A), or setting where prompt suggests a certain answer
faithfulness metric = model sensitivity to removing some of the explanation
Question Decomposition Improves the Faithfulness of Model-Generated Reasoning (anthropic, 2023) - introduce factored decomposition to improve faithfulness metric
Measuring Faithfulness in Chain-of-Thought Reasoning (anthropic, 2023) - in addition to just removing some of the explanation, also add mistakes to it / paraphrase it
larger models become less faithful by this metric
Do Models Explain Themselves? Counterfactual Simulatability of Natural Language Explanations (chen, zhong, …, steinhardt, yu, mckeown, 2023)
Logical Satisfiability of Counterfactuals for Faithful Explanations in NLI (sia…zettlemoyer, mathias, 2023)
Causal Proxy Models for Concept-based Model Explanations (wu…potts, 2023)
Two Failures of Self-Consistency in the Multi-Step Reasoning of LLMs (chen, …, bowman, cho, 2023) - models fail at these 2 tasks:
hypothetical consistency (the ability for a model to predict what its output would be in a hypothetical other context)
compositional consistency (consistency of a model’s outputs for a compositional task even when an intermediate step is replaced with the model’s output for that step)
Chain of Thought Prompting (wei et al. 2022)
in few-shot prompts, don’t just provide answer but also reasoning
model output then provides reasoning + answer
Self-Consistency Improves Chain of Thought Reasoning in Language Models (wang, wei, schuurmans, quoc le, … zhou, 2022) - use output samples rather than greedy and return the most consistent final answer in the set
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them (suzgun, …, quoc le, …, jason wei, 2022)
self-ask (Press et al., 2022) - LLM asks itself (and then answers) follow-up questions before answering the initial question
Text Classification via Large Language Models (sun…wang, 2023) - add clues to the prompt
Let’s Do a Thought Experiment: Using Counterfactuals to Improve Moral Reasoning (ma, …, chen, 2023) - counterfactuals help improve CoT
RCOT: Detecting and Rectifying Factual Inconsistency in Reasoning by Reversing Chain-of-Thought (xue et al. 2023)
SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning (miao, teh, & rainforth, 2023)
scratchpads Show Your Work: Scratchpads for Intermediate Computation with Language Models (nye et al. 2021)
selection inference (creswell et al. 2022) - generate set of facts, then iteratively generate inferences from the facts to yield the final answer
least-to-most prompting (zhou…quoc le et al. 2022) - prompt LLM with context showing how to reduce into subproblems; then LLM sequentially solves the subproblems, using the previous answers
Generated Knowledge Prompting for Commonsense Reasoning (liu…hasjishirzi, 2021) - generate knowledge from an LLM then provide it as additional input when answering a question
maieutic prompting (jung et al. 2022) - generate a tree of all explanation of the form “True, because…”, “False, because…” then query LLM with these as prompts
then use Max-SAT to try to satisfy as many relations between the model explanations as possible to come up with the true answer
review on self-verification (pan…wang, 2023)
LM vs LM: Detecting Factual Errors via Cross Examination (cohen et al. 2023)
Thread of papers combating hallucination
training
verifiers (cobbe et al. 2021) - train model to judge whether an answer and thought are likely to be “valid”
subgoal search (czechowski et al. 2021) - train model to generate subgoals then solve them in a graph
STaR “Self-taught reasoner” (zelikman…goodman, 2022)
first, finetune on observed \((Q, T, A)\) triplets, where \(T\) is a rationale
then, impute unknown \(T_i\) given dataset of pairs \((Q_i, A_i)\) by sampling until finding a \(T_i\) which leads to the correct answer
robotics-specific
zero-shot planning (huang, abbeel, pathak, & mordatch, 2022)
tree-related
tree of thoughts (yao et al. 2023) - LLM generates a tree of intermediate answers and perform steps such as backtracking
Graph of Thoughts: Solving Elaborate Problems with Large Language Models (besta, .., hoefler, 2023) - allows merging/looping in the tree, e.g. for sorting
Aug-tree (singh, askari, caruana, & gao, 2023)
frugalGPT (chen, zaharia, & zou, 2023)
3 components
prompt adaptation - identify effective / shorter prompts (e.g. less demonstrations)
LLM approximation - create simpler/cheaper LLMs
LLM cascade - adaptively choose LLM based on query
train “generation scoring function” - returns reliability score from 0 to 1 for each (question, answer)
router sequentially proceeds through LLM APIs, returning the answer if the reliability score is high enough
frugalML (chen, zaharia, zou, 2020) - tradeoff performance with budget for sequential cascade of API calls for single label
FrugalMCT (chen, zaharia, zou, 2022) - extends to multilabel
1.9.2.3. llm querying / causal inference#
decoding
Greedy - iteratively pick highest-probability token
Nucleus sampling: The Curious Case of Neural Text Degeneration (holtzman…choi, 2019)
Contrastive decoding (li et al. 2022) - decode based on the difference between a large and small LLM
Context-aware decoding (shi, …zettlemoyer, yih, 2023) - the difference between the output probabilities when a model is used with and without context
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models (chuang…he, 2023) - contasting later layers with early layers can improve truthfulness
Semantic Uncertainty (kuhn, gal, & farquhar, 2023) - yields uncertainties by incorporating linguistic invariances created by shared meanings
Minimum Bayes Risk Decoding (suzgun, …, jurafsky, 2022) or (freitag et al. 2022)
A Frustratingly Simple Decoding Method for Neural Text Generation (yang, …, shi, 2023) - build an anti-LM based on previously generated text and use this anti-LM to penalize future generation of what has been generated
Can Large Language Models Infer Causation from Correlation? (jin…scholkopf, 2023) - introduce Corr2Cause dataset (must infer causal graph from correlational statements), doesn’t test pre-existing knowledge
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality (kiciman…tan, 2023)
LLMs to be used alongside existing causal methods, as a proxy for human domain knowledge and to reduce human effort in setting up a causal analysis
cause-effect pairs, LLM has to discover from graph (tubingen benchmark, neuropathic pain, etc.)
Zero-shot causal learning (nilforoshan…leskovec, 2023)
Discovering Latent Knowledge in Language Models Without Supervision (burns, ye, klein, & steinhardt, 2022) - identify whether text is true or false directly from a model’s unlabeled activations
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model (li…pfister, wattenberg, 2023)
InferBERT: A Transformer-Based Causal Inference Framework for Enhancing Pharmacovigilance (wang…liu, 2021) - learn + test feature relationships from attention weights
CausaLM: Causal Model Explanation Through Counterfactual Language Models (2021) - produce example-level causal model explanations using models finetuned on auxiliary adversarial tasks derived from the causal graph of the problem
Investigating Gender Bias in Language Models Using Causal Mediation Analysis (vig, …, shieber, 2020)
Applies causal mediation analysis to identify decisive neurons and attention heads responsible for gender bias in large language models
Identifies a small handful of decisive attention heads in this case
Amnesic Probing: Behavioral Explanation with Amnesic Counterfactuals (elazar, …, goldberg, 2021) - measure the importance of specific info within a model by introducing a causal intervention to erase that information, then observing the causal effects
1.9.3. misc#
1.9.3.1. direct weight inspection#
Overview of mechanistic interpretability (nanda, 2022+) + review paper (rauker…hadfield-menell, 2023)
Transformer visualization via dictionary learning: contextualized embedding as a linear superposition of transformer factors (yun, chen, olshausen, lecun, 2021) - investigate LLM embeddings of different words using dictionary learning
LLMs produce interesting contextualized word embeddings
dictionary elements (of activations across layers) correspond to meaningful things
dictionary element has size \(d\), the embedding size
given list of sentences \(S\), training matrix has size \(\left(\underbrace{\text{num\_layers}}_{\text{12 for BERT}} \cdot \sum_{s \in S} \text{len(s)}\right) \times \underbrace{d}_{\text{768 for BERT}}\)
dictionary coefficient: maps (text, layer, sequence_index) \(\to\) coefficient
extract \(d\)-dimensional embedding for text at specified layer & sequence_index
Neuron-level Interpretation of Deep NLP Models: A Survey (sajjad et al. 2022)
previous works generally use pre-specified concepts, and focus on
concept search - given a neuron find its concept(s)
neuron search - (ii) given a concept find its matching neuron(s)
concept search
visualization, e.g. karpathy, johnson, fei-fei li, 2015 visualize LSTM head response in text
elicit top-k ngram responses on a corpus, which are then labelled manually (kadar et al. 2017)
elicit top-k activating sentences from a corpus, which are then summarized using a parse tree into a synthetic explanation (na…kim, 2019)
limitation: the explanation may be ungrammatical and biased towards something arbitrary (like reptition)
input maximization (e.g. textattack, poerner et al. 2018)
Evaluating Neuron Interpretation Methods of NLP Models (fan…sajjad, 2023) - metric is how well evaluation from one method matches the other ones
A Circuit for Indirect Object Identification in GPT-2 small (wang, …, steinhardt, 2022)
explanation encompasses 26 attention heads grouped into 7 main classes
task: indirect object identification - “When Mary and John went to the store, John gave a drink to ___” should be “Mary”
circuit
identify all previous names
remove duplicated names
output remaining name
Interpretability at Scale: Identifying Causal Mechanisms in Alpaca (wu…, potts, goodman, 2023) - propose boundless DAS and automatically identify a circuit for math
builds on DAS (geiger, …goodman, 2023)
N2G: A Scalable Approach for Quantifying Interpretable Neuron Representations in Large Language Models (foote, nanda, …, barez, 2023) - explain each neuron in a graph
Finding Skill Neurons in Pre-trained Transformer-based Language Models - some individual neurons are predictive of the final task (dubbed “skill neurons’)
thread (elhage…olah, 2021)
all layers are same dimension and each attention block adds a vector to it
Although they’re parameterized as separate matrices, \(W_O W_V\) and \(W_Q^T W_K\) can always be thought of as individual, low-rank matrices
\(x \in \mathbb R^{d_{embed} \times d_{sequence}}\): \(d_{embed}\) can be hundreds - tens of thousands
\(W_Q, W_K, W_V \in \mathbb R^{d_{attn} \times d_{embed}}\)
\(W_Q^TW_k \in \mathbb R ^{d_{embed} \times d_{embed}}\)
\(W_O \in \mathbb R^{d_{embed} \times d_{attn}}\): projects attention values back to embedding dimention
\(W_O W_V \in \mathbb R ^{d_{embed} \times d_{embed}}\)
\(W_E \in \mathbb R^{d_{embed} \times d_{vocab}}\) embeds initial tokens and \(W_U \in \mathbb R^{d_{vocab} \times d_{embed}}\) undoes the embedding
\(d_{vocab}\) can be very large, e.g. 50k
\(A = \text{softmax}(x^TW_Q^TW_kx) \in \mathbb R^{d_{sequence} \times d_{sequence}}\)
if we have a 0-layer net (e.g. predict next token with linear layer given current token), we just learn bigram log-likelihood
2 circuits
QK circuit determines which “source” token the present “destination” token attends back to and copies information from
\(W_{E}^{T} W_{Q}^{T} W_{K} W_{E} \in \mathbb R ^{d_{vocab} \times d_{vocab}}\)
OV circuit describes what the resulting effect on the “out” predictions for the next token is
\(W_{U} W_{O} W_{V} W_{E} \in \mathbb R ^{d_{vocab} \times d_{vocab}}\)
if a single head increases the probability of both
keep… in mindandkeep… at bay, it must also increase the probability ofkeep… in bayandkeep… at mindinduction heads search previous examples of present token
If they don’t find it, they attend to the first token and do nothing
if they do find it, they then look at the next token and copy it. This allows them to repeat previous sequences of tokens, both exactly and approximately
sometimes can do some kind of “fuzzy” matching
tensor/kronecker product \(\bigotimes\):
Left-right multiplying: Multiplying \(x\) by a tensor product \(A \otimes W\) is equivalent to simultaneously left and right multiplying: \((A \otimes W) x=A x W^{T}\)
When we add them, it is equivalent to adding the results of this multiplication: \(\left(A_{1} \otimes W_{1}+A_{2} \otimes W_{2}\right) x=A_{1} x W_{1}^{T}+A_{2} x W_{2}^{T}\) Softmax Linear Units
replacing activation function with softmax linear unit increases fraction of MLP neurons which are “interpretable”, i.e. correspond to meaningful features
however, may “hide” some non-neuron-aligned features by decreasing their magnitude and then later recovering it with LayerNorm
the presence of nonlinear activation functions createse an incentive for features to align with this basis and not get superposed
if the gains to sparse coding are large enough, this incentive will get overwhelmed
ways to combat polysemanticity
activation sparsity
lateral inhibition / co-occurrence sparsity
weight sparsity
superlinear activation functions
increase neurons per param
\(\text{SoLU}(x) = x \cdot \text{softmax}(x)\)
adds lateral inhibition, superlinearity, approximate sparsity
changes GeLU, which is approximately \(\text{sigmoid}(1.7x) \cdot x\)
just changing to SoLU decrease performance, had to add LayerNorm afterwards
logit lens (2020) - apply unembedding matrix to outputs of each transformer layer
tuned-lens (belrose…steinhardt, 2023) - train linear model for each layer to decode vocab
Analyzing Transformers in Embedding Space (dar, …, berant, 2022) - apply unembeddix matrix to weights, etc. to interpret transformers
Rosetta Neurons: Mining the Common Units in a Model Zoo (dravid, …, efros, shocher, 2023)
Multimodal Neurons in Pretrained Text-Only Transformers (schwettmann…torralba, 2023)
The Hydra Effect: Emergent Self-repair in Language Model Computations (mcgrath…legg, 2023) - ablations atone attention layer of an LLM cause another layer to compensate
Neurons in Large Language Models: Dead, N-gram, Positional (voita, ferrando, & nalmpantis, 2023)
1.9.3.2. attention variants#
Tree Transformer: Integrating Tree Structures into Self-Attention (wang, .., chen, 2019)
Waveformer: Linear-Time Attention with Forward and Backward Wavelet Transform (zhuang…shang, 2022)
1.9.3.3. editing#
Editing Large Language Models: Problems, Methods, and Opportunities (yao, …, zhang, 2023)
model-editing = data-efficient alterations to a model
memory-based
SERAC: Memory-Based Model Editing at Scale (mitchell…manning, finn, 2022)
keep track of list of edits in external memory and use them as appropriate context at test time (don’t finetune the model)
T-Patcher (Huang et al., 2023) and CaliNET (Dong et al., 2022) introduce extra trainable parameters into the feed- forward module of PLMs
weight updates
Knowledge Neurons in Pretrained Transformers (dai et al. 2021) - integrated gradients wrt to each neuron in BERT, then selectively udpate these neurons
ROME: Locating and Editing Factual Associations in GPT (meng, bau et al. 2022 )
localize factual associations - causal intervention for identifying neuron activations that are decisive in a model’s factual predictions
“causal traces” - run net multiple times, introducing corruptions and then restore states from original non-corrupted forward pass to see which states can restore the original results
a small number of states contain info that can flip the model from one state to another
change factual associations - modify feedforward weights to update specific factual associations using Rank-One Model Editing (ROME)
MEMIT: Mass Editing Memory in a Transformer (meng…, bau, 2022)
Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adapters (hartvigsen, …, palangi, …, ghassemi, 2023)
meta-learning
KnowledgeEditor: Editing Factual Knowledge in Language Models (de cao, aziz, & titov, 2021) - train a network that takes in input, output, edit and predicts a weight update to the model
MEND: Fast model editing at scale (mitchell…finn, manning, 2022)
a collection of small auxiliary editing networks that use a single desired input-output pair to edit a pre-trained model
MEND learns to transform the gradient obtained by standard fine-tuning, using a low-rank decomposition of the gradient
REMEDI (hernandez, li, & andreas, 2023) and related activation engineering
get “edit vectors” by obtaining embeddings when passing attributes through LLM
perform edit by by adding linear transformation of edit vector to prompt embedding
then, perform generation with latent embedding
learn linear transformation given a dataset of examples with attributes and desired completions
(also regularize the model to not change too much on other stuff)
activation engineering: Steering GPT-2-XL by adding an activation vector (turner, …, mini, 2023)
obtain “steering vector” by embedding a phrase (e.g. love) and adding that vector to the llm embedding during generation
they only add the embedding for some layers for some tokens
Extracting Latent Steering Vectors from Pretrained Language Models (subramani, …, peters, 2022) - find latent vectors via optimization that cause an LLM to output a particular sequence
then, use these vectors to do things like transfer to new tasks / compute textual similarity
PURR: Efficiently Editing Language Model Hallucinations by Denoising Language Model Corruptions (chen…sameer singh…kelvin guu, 2023)
new datasets
MQUAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions (zhong…manning, potts, chen, 2023) - introduces benchmark MQUAKE + method MeLLo, which stores edited facts externally while prompting the language model iteratively to generate answers that are consistent with the edited facts
COUNTERFACT+ benchmark - checks that edits don’t affect existing info
1.9.3.4. debugging / interpretation#
TalkToModel: Understanding Machine Learning Models With Open Ended Dialogues (slack…lakkaraju, sameer singh, 2022) - natural language interface to query model (by converting to commands such as filtering the data / calculating importance)
Rethinking Explainability as a Dialogue: A Practitioner’s Perspective (lakkaraju, slack, …, sameer singh, 2022) - interviews with high-stakes users suggest they would like to be able to interact with systems via dialog
The Unreliability of Explanations in Few-shot Prompting for Textual Reasoning (ye & durrett, 2022)
AdaTest: Adaptive Testing and Debugging of NLP Models (ribeiro & lundberg, 2022)
goal: easily specify, discover, and fix undesirable behaviors in an NLP model
2-step iterative algorithm
LLM generates many tests targeting the model’s failures
example of a test:
f(“I am a black woman”) ≠ neguser selects and organizes the tests and reprompts the LLM to find more
User fixes the tests (e.g. via finetuning)
Checklist Beyond Accuracy: Behavioral Testing of NLP models with CheckList (ribeiro…sameer singh, 2020)
matrix of general linguistic capabilities + test types
Fixing Model Bugs with Natural Language Patches (murty, manning, lundberg, & ribeiro 2022)
specify patches with natural language rather than hard rule, allowing them to better handle text
finetune a model to combine original model output with output from a patch-conditioned interpreter head
Aug-imodels: Augmenting Interpretable Models with LLMs during Training (singh, askari, caruana, & gao, 2023)
1.9.3.5. symbolic reasoning#
See also notes on 📌 comp neuro.
GPT-3 Large Language Models are Zero-Shot Reasoners - simply adding “Let’s think step by step” before each answer increases the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with GPT-3
Compositional processing emerges in neural networks solving math problems (russin, roland fernandez, …, smolensky, gao, 2021)
Modular Deep Learning (pfeiffer, ruder, .., ponti, 2023) - overview of different modular architectures
neurocompositional computing (smolensky…gao, 2022)
longer tutorial (smolensky, …, gao, 2022)
central paradox of cognition is that brain both uses continuous neural symbols but is compositional (smolensky et al. 1992)
Compositionality
Continuity - the encoding and processing of information is formalized with real numbers that vary continuously
3 challenges
compositional generalization
data efficiency
comprehensibility
solution - NECST: Neurally-Encoded Compositionally-Structured Tensor computing (smolensky & legendre, 2006) - basically leverages TPR
TPR roles and fillers can both be made continuous
neural space vs symbolic space (many different things (e.g. sentences) can mean the same thing)
word vectors can be thought of as “soft symbols”
want to move from symbolic repr. to neural repr. while keeping interpretability
system should output intermediate steps in addition to answer
thinking fast (system 1: fast, intuitive) + slow (system 2: slower, logical, derivative)
concrete proposals
transformer activation vector should encode graph of flow through the network
ex. task: regurgitate a sequence
TPR: Tensor product variable binding and the representation of symbolic structures in connectionist systems (paul smolensky, 1990) - activation patterns are “symbols” and internal structure allows them to be processed like symbols
tensor product representation = TPR
TPR of a structure is the sum of the TPR of its constituents
tensor product operation allows constituents to be uniquely identified, even after the sum (if roles are linearly independent)
filler - one vector that embeds the content of the constituent
role - second vector that embeds the structural role it fills
NECSTransformer: Enhancing the Transformer with Explicit Relational Encoding for Math Problem Solving (schlag, …, gao, 2019)
TP-attention
beat SOAon free-form math word-problems
in addition to K, Q, V, also add a role-vector
do element-wise multiplication of outputted vector with role-vector
TPR built as tensor product of 2 vectors:
filler - the vector returned by attention
ex. one head learns “second-argument-of”
role - a relation conceptually labeling an edge of the attention graph
TP-N2F: Tensor Product Representation for Natural To Formal Language Generation - Microsoft Research (chen…gao, 2019)
Logical Transformers: Infusing Logical Structures into Pre-Trained Language Models (wang, huang, …, gao, 2023) - use logical model to alter embeddings before feeding to LLM
1.9.3.6. adaptation / transfer#
These are transformer-specific. For more general notes, see 📌 transfer learning or 📌 uncertainty. Most of these approaches can be combined with metalearning.
finetuning
finetune all DNN params
finetune linear layer on activations
standard - train linear model on the embedding of the first token (usually an added
[CLS]token) (peters et al. 2018)finetune linear model on all the activations
e.g. evci, et al. 2022 - learn linear layer (using group-lasso) on features extracted from all layers
finetune specific DNN params (e.g. just the bias terms)
Cutting Down on Prompts and Parameters (logan…sameer singh, riedel, 2021) - finetune only the bias terms; works even with null prompts
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models (zaken, ravfogel, & goldberg, 2021) - finetune only bias terms
adapter - finetune lightweight layers on top of pre-trained layers (between finetuning all layers, and just finetuning a new layer)
add some new layers and retrain some specific things (all human choices)
side-tuning (zhang, sax…malik, 2020) - train a “side” network that is fused with the pretrained model via summation
Combining Modular Skills in Multitask Learning (ponti, sordoni, bengio, & reddy, 2022) - learn adaptor with disentangled inventory of skills
vaguely similar to adapter
LoRA
QLoRA: Efficient Finetuning of Quantized LLMs (dettmers, …, zettlemoyer, 2023)
TOAST (shi, …, darrel, xin wang, 2023) - use top-down attention steering for efficient finetuning
predict a mask
ablate some model weights by training a binary mask over model parameters (Zhao et al., 2020; Radiya-Dixit and Wang, 2020)
predict mask over attention heads
prompting = few-shot learning = priming = in-context learning (starts with GPT)
prompting without changing any model parameters
limitation: can’t exploit sets longer than the training window
MetaICL: Learning to Learn In Context (min et al. 2022) - tune LLM to do in-context learning on a large set of training tasks (few-show prompting and training time and at test-time)
Visual Prompting via Image Inpainting (bar…darrell, globerson, efros, 2022)
PatternExploiting Training (PET) – Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference (schick & schutze, 2021)
cloze questions - same as masked language modeling: task is to replace some missing words
use cloze-question templates (e.g. it was “good” or “bad”) to get soft labels for unlabeled data and then finetune on theses
prompt-tuning (also see next section on autoprompting)
Attentional Mixtures of Soft Prompt Tuning for Parameter-efficient Multi-task Knowledge Sharing
Mixture of Soft Prompts for Controllable Data Generation (chen, … yu, 203) - LLMs as Synthetic Data Generators for Training Smaller Models
mt-dnn line of work
Multi-Task Deep Neural Networks for Natural Language Understanding (xiaodong liu … gao 2019) - multi-task learning on the 9 glue tasks (first layers are shared, then some task-specific layers at top)
RAdam: On the Variance of the Adaptive Learning Rate and Beyond (liyuan liu…gao, han, 2020)
usually need to do learning-rate warmup when trainin (e.g. with Adam)
RAdam = add a term to rectify the variance of the adaptive learning rate in Adam
SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization (jiang…gao, zhao, 2020)
Smoothness-inducing regularization, which effectively manages the complexity of the model
Bregman proximal point optimization to prevent aggressive updating
Microsoft Toolkit of Multi-Task Deep Neural Networks for Natural Language Understanding (xiaodong liu…gao, 2020)
Posterior Differential Regularization with f-divergence for Improving Model Robustness (hao cheng, …, gao 2021)
regularize model posterior difference between clean + noisy inputs (e.g. adversarially attacked inputs)
comparing different tasks
Task2Vec: Task Embedding for Meta-Learning (achille, …, soatto, perona, 2019) - summarize each task as a vector, by taking diagonal of fisher info matrix (derivative of network output wrt to parameters) - clusters similar tasks
Efficiently Tuned Parameters are Task Embeddings (zhou…mcauley, 2022)
Editing Models with Task Arithmetic (ilharco, ribeiro, …, farhadi, 2022) - task vector is model weights after task finetuning - model weights before finetuning
can use this direction to alter model behavior
Overcoming Catastrophic Forgetting in Zero-Shot Cross-Lingual Generation (vu….constant, 2022) - train with prompts of some (language translation, task) pairs and show that they can generalize to new (language, task) pairs
1.9.3.7. model merging / mixture of experts (MoE) / routing#
mixture of experts models have become popular because of the need for (1) fast speed / low memory at test time while still (2) having a large model during training
note: nowadays often the “experts” are different MLPs following the self-attention layers
A Review of Sparse Expert Models in Deep Learning (fedus, jeff dean, zoph, 2022)
sparsity decouples the parameter count from the compute per example allowing for extremely large, but efficient models
routing algorithm - determines where to send examples
discreteness makes it difficult
some works use RL to learn routing
standard approach uses gumbel-softmax
usually get matrix of similarities between input tokens and experts and route based on these
sometimes route to topk experts rather than top1
load balancing - usually add an auxiliary loss to encourage equal tokens being sent to different experts
non-specialized experts
Early versions (Jacobs, michael jordan, nowlan, & hinton, 1991) had independent feed-forward networks serving as experts
Sparsely-gated MOE layer (Shazeer…quoc le, hinton, dean, 2017) have been studied with token-based routing with backprop
replace FFN in transformers with expert layers
GShard Lepikhin et al. (2021), which appplies this concept to machine translation
Switch transformers (Fedus et al. (2022)) simplifies the architecture to activation of only one expert per layer
BASE Layers Lewis et al. (2021) - find an alternative approach to routing by formulating it as a linear assignment problem
Hash layers Roller et al. (2021) use a fixed hash as the gating function
routing notes - make hard decision but still want to learn probabilities
straight-through estimator (STE) - take the argmax during the forward pass, while considering the orig- inal probabilities in the backward pass
highly biased
gumbel-softmax- allows for better sampling
specialized experts as fully independent models (sometimes for multi-task learning)
DEmix Layers Gururangan et al. (2022) – DEMix layers – placed in the feedforward layers of the Transformer – contain experts which specialize on specific domains. Routing at train time is determined only by the domain label, but all experts are activated at inference time and mixed according to weights estimated from a validation set
Sparsely Activated Mixture-of-Experts are Robust Multi-Task Learners (gupta…awadallah, gao, 2022) - use task description to improve routing
Pfeiffer et al. (2022) - multilingual expert model with language-specific routing
task-level MoE Kudugunta et al. (2021) – multi-task expert model with task-specific routing
scaling up
OPT-MOE (artetxe et al. 2021)
AutoMoE (jawahar, mukherjee, liu…gao, 2022)
Interpretable entity representations through large-scale typing (onoe & durrett, 2020) - embedding is interpretable predictions for different entities/
Towards Understanding Mixture of Experts in Deep Learning (chen…gu, li, 2022)
model merging (some of these are non-transformer papers) = combine different models that have the same architecture
model soups (wortsman…schmidt, 20221) - average weights of finetuned models
snapshot ensembles - average different checkpoints during training (huang et al. 2017)
stochastic weight averaging (izmailov, …, wilson, 2019) - average multiple checkpoints during training
batch ensemble (wen et al. 2020) - have several rank-1 keys that index different weights hidden within one neural net
ELMS – Branch-Train-Merge (li et al. 2022)
parallel language model of smaller expert LMs
each can be added/removed, ensembled, or parameter-averaged at any time for efficient scaling and rapid customization
improves perplexities, when controlling for training cost
require expert domain specialization
Merging Models with Fisher-Weighted Averaging (matena & raffel, 2022) - merge models with same architecture with particular weights
An Empirical Study of Multimodal Model Merging (sung…wang) - merge a separately trained vision & language model and get a multiomodal model
TIES: Resolving Interference When Merging Models (yadav…raffel, bansal, 2023) - empirical heuristics for merging model weights specific to tasks, e.g. vote on signs of parameters
fit many models into one
superposition of many models into one (cheung…olshausen, 2019) - both during training/testing models are indexed via a high-dim key for each task
supermasks in superposition (wortsman, …, yosinski, farhadi, 2020) - randomly fixed based net + for each task finds subnet that chieves good performance
if task identity not given, correct subnet inferred by minimizing output entropy
Git Re-Basin: Merging Models modulo Permutation Symmetries (ainsworth, hayase, & srinivasa, 2022) - algo to merge models even when they haven’t been pretrained together
early exit - popular way to speed up inference
Multi-exit vision transformer for dynamic inference (Bakhtiarnia, A., Zhang, Q. and Iosifidis, A., 2021)
early layers have large activation map so early exist classifier must be complex
solution: ViT class token allows early-exit classifier to have constant complexity
DeeBERT: Dynamic early exiting for accelerating BERT inference (xin…lin, 2020)
1.9.3.8. embeddings#
Instructor: One Embedder, Any Task: Instruction-Finetuned Text Embeddings (su, …, smith, zettlemoyer, yu, 2022) - embedding is contextualized to eaach task
Text Embeddings Reveal (Almost) As Much As Text (2023)
Explaining embeddings
Computer-vision focused
Axiomatic Explanations for Visual Search, Retrieval, and Similarity Learning (hamilton, lundberg…freeman, 2021) - add in “second-order” methods that look at similarities between different image features in the 2 images being compared
Why do These Match? Explaining the Behavior of Image Similarity Models (plummer…saenko, forsyth, 2020) - generate saliency map + with an attribute based on the salient region
Towards Visually Explaining Similarity Models (zheng…wu, 2020) - similarity of cnn embeddings
Explaining similarity with different outputs
Analogies and Feature Attributions for Model Agnostic Explanation of Similarity Learners (ramamurthy…tariq, 2022) - returned explanation is an analogy (pair from the training set) rather than a saliency map
Sim2Word: Explaining Similarity with Representative Attribute Words via Counterfactual Explanations (chen…cao, 2023) - give both saliency map + counterfactual explanation
1.9.3.9. pruning#
SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot (frantar & alistarh, 2023) - prune GPT-style models to atleast 50% sparsity in one-shot, without any retraining, at minimal loss of accuracy
Cramming: Training a Language Model on a Single GPU in One Day (geiping & goldstein, 2022) - tricks for training BERT
1.9.4. applications#
1.9.4.1. dataset / module explanation#
dataset explanation
iPrompt: Explaining Patterns in Data with Language Models via Interpretable Autoprompting (singh, morris, …gao, 2022 ) - prompting approach
Instruction Induction: From Few Examples to Natural Language Task Descriptions (honovich…bowman, levy 2022) - directly query model with prompt to search for task description
D3: Describing Differences between Text Distributions with Natural Language (zhong, snell, klein, & steinhardt, 2022) - finetune an LLM to directly describe difference between 2 text distrs
D5: Goal Driven Discovery of Distributional Differences via Language Descriptions (zhong, zhang, …, klein, & steinhardt, 2023) - add dataset-specific prompt + evaluation on larger set of 675 datasets
technically this is just learning a classifier, where the classifier is a natural-language string
method
proposer network generates hypotheses
verifier networks looks at all samples in the dataset (since proposer couldn’t fit them all in context) and returns how accurate the hypotheses were
some tricks
select samples which are “representative” of a class by predicting with another LLM
have a pool of 302 manual hypotheses they usefor seeding
Goal-Driven Explainable Clustering via Language Descriptions (wang…, zhong, 2023)
ClusterLLM: Large Language Models as a Guide for Text Clustering (zhang…shang, 2023)
LLMs4OL: Large Language Models for Ontology Learning (giglou et al. 2023) - use prompting to construct ontologies
Towards Ontology Construction with Language Models (funk…lutz, 2023)
Mass-Producing Failures of Multimodal Systems with Language Models (tong, jones, & steinhardt, 2023)
GSCLIP : A Framework for Explaining Distribution Shifts in Natural Language (zhu…james zou, 2022) - automatically explain dataset-level distribution shifts (in image datasets) with natural language
MaNtLE: Model-agnostic Natural Language Explainer (menon, zaman, & srivastava, 2023) - train model to generate explanations on simple tables (they do this for classifier outputs but could easily do it directly for data labels)
Large Language Models for Automated Open-domain Scientific Hypotheses Discovery (yang…cambria, 2023)
module explanation in natural language
Explaining black box text modules in natural language with language models (singh, hsu, …, gao, 2023)
Language models can explain neurons in language models (bills, cammarata, …saunders, 2023, openai)
goal: explain a neuron
step 1: summarize (token, activation) pairs into an explanation
step 2: create simulated neuron that outputs activations given tokens
step 3: check correlation of simulated neuron outputs with real neuron outputs
their unigram baseline summarizes top unigrams into a string
they use synthetic generated data to revise the explanation
they also do some recovery tests on “neuron puzzles”
MILAN: Natural Language Descriptions of Deep Visual Features (hernandez…david bau…torallba, andreas, 2022) - given a neuron, generates a natural-language string that maximizes pointwise mutual information with the image regions in which the neuron is active
Scale Alone Does not Improve Mechanistic Interpretability in Vision Models (zimmermann, klein, & brendel, 2023) - perform human eval of interpretability of different units (show human top-activating patches and ask them to decide which of 2 patches will be top-activating)
A Function Interpretation Benchmark for Evaluating Interpretability Methods (schwettmann, …, andreas, bau, & torralba, 2023)
1.9.4.2. learning algorithms#
Empirical results
Discovering faster matrix multiplication algorithms with reinforcement learning (deepmind, 2022)
Faster sorting algorithms discovered using deep reinforcement learning (deepmind, 2023)
Nuclear fusion control (deepmind, 2022)
What Can Transformers Learn In-Context? A Case Study of Simple Function Classes (garg, tsipras, liang, & valiant, 2022) - models can succesfully metalearn functions like OLS
e.g. during training, learn inputs-outputs from different linear functions
during testing, have to predict outputs for inputs from a different linear function
also test on slightly harder functions, like decision trees and 2-layer nets
Learning a (sparse) linear model
The contextual lasso: Sparse linear models via deep neural networks (thompson, …, kohn, 2023) - very rough results…
What learning algorithm is in-context learning? Investigations with linear models - investigate prompting through synthetic experiments with transformers trained for linear regression
Transformers as Algorithms: Generalization and Implicit Model Selection in In-context Learning (li, …, oymak, 2023) - generalization bounds for in-context learning when the input prompt is (1) a sequence of i.i.d. (input, label) pairs or (2) a trajectory arising from a dynamical system
Trained Transformers Learn Linear Models In-Context (zhang, frei, & bartlett, 2023)
One Step of Gradient Descent is Provably the Optimal In-Context Learner with One Layer of Linear Self-Attention (Mahankali, Hashimoto, Ma, 23)
math analysis for: icl can do gradient decent on linear regression
Pretraining task diversity and the emergence of non-Bayesian in-context learning for regression (raventos, … ,ganguli, 2023)
Teaching Algorithmic Reasoning via In-context Learning (zhou…sedghi, 2022)
Looped Transformers as Programmable Computers (giannou, …, jason lee, papailiopoulos, 2023 - use transformers as universal computers by programming them with specific weights
Learning mathematical problems (francois charton)
Negative results
Faith and Fate: Limits of Transformers on Compositionality (dziri…choi, 2023) - LLMs can’t (easily) be trained well for multiplication (and similar tasks)
Theory (don’t directly predict algorithm)
Meta-learning for Mixed Linear Regression (kong…kakade, oh, 2020) - generalization for linear regression based on which linear tasks were seen before
1.9.4.3. cool tasks#
Forecasting Future World Events with Neural Networks (zou…hendrycks, 2022) - takes tasks from metaculus
Shortcut Learning of Large Language Models in Natural Language Understanding: A Survey (du et al. 2022)
Neurosymbolic Programming for Science (sun…costilla-reyes, 2022)
Discovering New Interpretable Conservation Laws as Sparse Invariants (liu…tegmark, 2023) - does not use transformers
evaluation without groundtruth
Evaluating Superhuman Models with Consistency Checks (fluri, …, tramer, 2023)
Learning from learning machines: a new generation of AI technology to meet the needs of science (berkeley+lbnl+, 2021)
do more than predict what will happen, they attempt to offer insight into how or why
AI-based language models powering drug discovery and development (liu et al. 2021)
BioTranslator: Multilingual translation for zero-shot biomedical classification (xu, woicik, poon, altman, & wang, 2023) - takes a user- written textual description of a new concept and then translates this description to a non-text biological data instance
results for biological data, e.g. genes, proteins
enables the identification of novel cell types using only a textual description
Learning to Generate Novel Scientific Directions with Contextualized Literature-based Discovery (wang…hope, 2023)
literature-based discovery (swanson, 1986) - focus on predicting pairwise links between concepts from papers (e.g. drug-disease links)
task 1: idea-sentence generation – given sentences describing background context + a seed term, generate a sentence describing an idea
task 2: idea-node prediction – given the background context, predict new links between existing concepts (and generate new concepts)
forecasting paper titles (blog post)
scientific organization (galactica)
related but smaller models
SciBERT (beltagy…cohan, 2019)
BioLM (lewis…stoyanov, 2020)
ScholarBERT (hong…foster, 2022) - large dataset, 770M-param model
all data is processed in a common markdown format
task-specific tokens to support different types of knowledge (e.g. citations, step-by-step reasoning, different modalities, e.g. proteins)
chemical compounds (train on 2 mil / 110 mil from PubChem Compound, authors still want it to focus on text)
predict IUPAC name from SMILES formula e.g.
CC(C)(C)C(=O)N(CC1=NC(=CS1)C(=O)OC)C2CCCCC2->methyl 2-[[cyclohexyl-(2,2-dimethylpropanoyl)]amino] methyl]thiazole-4-moleculenet (wu et al. 2017) classification benchmark (6 tasks)
training set examples are trained as text during fitting
HIV - classify whether comopund inhibits HIV replication
BACE C - binding results (classification + regression) for BACE
BBBP - blood-brain barrier penetration(permeability) (binary classification)
Tox21 - qualitative toxicity on 12 targets (12-class multilabel binary)
SIDER - 27-class multi-class disorders in different organ systems
ClinTox - binary toxicity classification
ex. for BBBP (one of the 6 tasks) - question is posed in different ways during training
Here is a SMILES formula: [START_I_SMILES]O=C(O)CCCC1=CC=C(N(CCCl)CCCl)C=C1[END_I_SMILES] Question: Will the chemical compound penetrate the blood-brain barrier? Answer: No
protein sequences
from 227 million in UniProt, look at only 0.5 million subset (called Swiss-Prot)
evaluate protein sequence perplexity
protein keyword prediction (predict keywords in UniProt, like “ATP-Binding”, “Cell membrane”)
protein function description - compare free-form description to GT UniProt function description
1.9.4.4. tabular data#
tabular pre-training
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second (hollman, …, hutter, 2022)
transformer takes in train + test dataset then outputs predictions
each row (data example) is treated as a token and test points attend only to training t
takes fixed-size 100 columns, with zero-padded columns at the end (during training, randomly subsample columns)
builds on prior-data fitted networks (PFNs) (muller, …, hutter, 2021)
trained on synthetic data
GPT for Semi-Automated Data Science: Introducing CAAFE for Context-Aware Automated Feature Engineering (hollman, …, hutter, 2023)
TabDDPM: Modelling Tabular Data with Diffusion Models (2022)
TabLLM: Few-shot Classification of Tabular Data with Large Language Models (hegelsmann…, sontag, 2022)
TabRet: Pre-training Transformer-based Tabular Models for Unseen Columns
TABBIE (Iida, …, Iyyer, 2021) - average row/column embeddings
(not using transformers): transform a relation table in a graph and perform random walks on the latter to produce node embeddings (Cappuzzo et al., 2020)
Language models are weak learners (manikandan, jian, & kolter, 2023) - use prompted LLMs as weak learners in boosting algorithm for tabular data
input representation
baseline methods: usually flatten tables, maybe with special character for starting each row/col
could combine output from rows/cols with using element-wise product, average pooling and concatenation (TABULARNET)
sometimes add column headers to cell content
also popular is converting the table-to-text with finetuned models before processing
older
TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data (yin, neubig, …, riedel, 2020)
one-off tasks
LLMS are realistic tabular data generators (borisov et al. 2022)
Can Foundation Models Wrangle Your Data? (narayan…re, 2022)
reviews
Transformers for Tabular Data Representation: A Survey of Models and Applications (badaro…papotti, 2023)
common data sources: Wikipedia tables for QA (e.g. 3.2M tables in this paper) or WDC web table corpus (233M tables from lehmberg et al. 2016)
modifications
positional embeddings based on rows + cols
attention variants: add row-wise, sparse attention allows for adding more context
Table Pre-training: A Survey on Model Architectures, Pretraining Objectives, and Downstream Tasks (2022)
Embeddings for Tabular Data: A Survey (singh & bedathur, 2023)
Deep neural networks and tabular data: A survey (2022) - mostly compares performance on standard tasks (e.g. classification)
1.9.4.5. llm limitations / perspectives#
Dissociating language and thought in large language models: a cognitive perspective (mahowald, …, tenenbaum, fedorenko, 2023)
2 competences: (1) formal & (2) functional linguistic competence
speculative foundation models paper (stanford, 2022)
1.9.4.6. text explanations (pre-CoT)#
WT5?! Training Text-to-Text Models to Explain their Predictions (narang, raffel, …, malkan, 2020)
Adversarial Inference for Multi-Sentence Video Description - adversarial techniques during inference for a better multi-sentence video description
Object Hallucination in Image Captioning - image relevance metric - asses rate of object hallucination
CHAIR metric - what proportion of words generated are actually in the image according to gt sentences and object segmentations
women also snowboard - force caption models to look at people when making gender-specific predictions
Fooling Vision and Language Models Despite Localization and Attention Mechanism - can do adversarial attacks on captioning and VQA
Grounding of Textual Phrases in Images by Reconstruction - given text and image provide a bounding box (supervised problem w/ attention)
eli5 has nice text highlighting for interp
1.9.4.7. clinical papers#
Self-Verification Improves Few-Shot Clinical Information Extraction (gero et al. 2023)
Large Language Models are Few-Shot Clinical Information Extractors (agrawal…sontag, 2022) - use GPT3
Health system-scale language models are all-purpose prediction engines (NYU 2023)
GPT4 in medicine book (lee, goldberg, & kohane, 2023)
For summaries: “Can you check the proposed note and identify any facts in it that don’t appear explicitly in the transcript?”
gpt often better at reviewing text than writing it
evaluation
hard to run gpt clinical trial, although can be used to identify candidates, e.g. biomarkers for followup tests
paperwork - replace patient intake form, medical encounter note, prior authorization note (to insurance), universal translator for health info / formatting
Evaluating Large Language Models on Medical Evidence Summarization (tang…peng, 2023) - score summaries based on 6 dimensions (e.g. coherence)
Summarizing, Simplifying, and Synthesizing Medical Evidence Using GPT-3 (with Varying Success) (shaib…wallace, 2023)
SummIt: Iterative Text Summarization via ChatGPT (zhang, …, zhang, 2023)
1.9.4.8. evaluating with LLMs#
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment (liu…zhu, 2023, microsoft) - ask for a score (1-5) in different categories, e.g. fluency, relevance, …
Human-like Summarization Evaluation with ChatGPT (gao…wan, 2023) - prompt-based scoring of different categories, facts
Question-answering
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation (min…hajishirzi, 2023) - breaks a generation into a series of facts and count what fraction of facts are supported by a reliable knowledge source
PRD: Peer Rank and Discussion Improve Large Language Model based Evaluations (li…du, 2023)
Machine-translation
Towards Explainable Evaluation Metrics for Machine Translation (leiter…eger, 2023)
General NLG
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate (chan…liu, 2023)
AlignScore: Evaluating Factual Consistency with a Unified Alignment Function (zha…hu, 2023) - train a model to explicitly evaluate factual consistency
Not All Metrics Are Guilty: Improving NLG Evaluation with LLM Paraphrasing (tang…wei, 2023)
Classical eval
ROUGE, BLEU
BERTScore, BLEURTScore
Trained llms
ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation (wang, …, li, 2023)
BioGPT: Generative pre-trained transformer for biomedical text generation and mining (luo…poon, liu, 2022)
ChatDoctor (finetuned LLAMA) (yunxiang, …, you, 2023)
PubMedGPT (2.7B): (bolton, hall, …, manning, liang, 2022) -> renamed to BioMedLM
BioBERT: A pre-trained biomedical language representation model for biomedical text mining (2019)
PubMedBERT: Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing (gu…gao, poon, 2021)
Med-PaLM 2 (google, 2023) - state of the art QA
Large Language Models Encode Clinical Knowledge (singhal, …, natarajan, 2022, google/deepmind) - introduce MultiMedQA dataset + derive Med-PaLM, a prompt-tuned version of PaLM
PMC-LLaMA (wu et al. 2023)
1.9.4.9. privacy#
Training Data Extraction From Pre-trained Language Models: A Survey (ishihara, 2023)
definitions
(eidetic memorization). A string s is k-eidetic memorized by LLMf if a prompt p exists such that f(p) = s and s appears at most k times in the training set
slightly different definition: A string s is k-memorized with k tokens of context from LLM f if a (length-k) string p exists such that the concatenation p + s is contained in the training set, and f produces s when prompted with p by using greedy decoding
Differential privacy = removing any data from the training set should not considerably change trained models
counterfactual memorization = difference between a training data’s expected loss under a model that has and has not been trained on that data
some studies loosen the definition of memorization using a similarity metric for strings rather than exact string matching
Extracting Training Data from Large Language Models (carlini, …, raffel, 2021) - LLMs are particularly likely to memorize atypical data points
Quantifying Memorization Across Neural Language Models (carlini, …, zhang, 2022)
What does it mean for a language model to preserve privacy? (brown, …, tramer, 2022) - “privacy-preserving” LM should guarantee that a user’s data cannot ever appear (or be inferable) outside the context they originally expected it to appear in
Can Neural Network Memorization Be Localized? (maini, …, lipton, kolter, zhang, 2023) - memorization is often confined to a small number of neurons or channels, propose example-tied dropout to direct memorization to few neurons
Detecting Personal Information in Training Corpora: an Analysis (subramani, luccioni, dodge, & mitchell, 2023)
1.9.4.10. paper parsing#
Nougat: Neural Optical Understanding for Academic Documents (blecher…scialom, sojnic, 2023)
PDFTriage: Question Answering over Long, Structured Documents (adobe, 2023)
1.9.5. basics#
attention = vector of importance weights
to predict or infer one element, such as a pixel in an image or a word in a sentence, we estimate using the attention vector how strongly it is correlated with (or “attends to” other elements and take the sum of their values weighted by the attention vector as the approximation of the target
vanilla transformer: multihead attention, add + norm, position-wise ffn, add + norm
self-attention layer implementation, mathematics, and chandan’s self-attention cheat-sheet
1.9.5.1. mathematical overview of transformers (Formal Algorithms for Transformers)#
tasks
sequence modeling: learn \(p(x)\), usually factorized as \(p(x_i|x_1,...,x_{i-1})\)
sequence-to-sequence: learn \(p(z|x)\), e.g. transalation, speech-to-text, question answering
preprocessing
embedding matrix takes in one-hot tokens and linearly maps them to a vector
positional embedding of a token is usually added to the token embedding to form a token’s initial embedding
attention types
Bidirectional / unmasked self-attention - primary/context vectors are the same
Unidirectional / masked self-attention - mask scores from before a given word
Cross-attention - primary/context vectors can come from different places
non-attention
layernorm: controls mean/variance of activations
RMSnorm: simpler version, sets mean/offset to zero
unembedding
linear layer (with softmax) that outputs size of original vocab
sometimes fixed to be transpose of the embedding matrix
predictions
predict next word using single linear layer on hidden state from previous word
finetune classification head often only using linear layer on first token from sequence
architectures
initially, encoder-decoder was common, but now often no decoder
1.9.5.2. visual explanation (notes on article by jay allamar)#
**self-attention ** - layer that lets word learn its relation to other layers
for each word, want score telling how much importance to place on each other word (queries \(\cdot\) keys)
we get an encoding for each word
the encoding of each word returns a weighted sum of the values of the words (the current word gets the highest weight)
softmax this and use it to do weighted sum of values
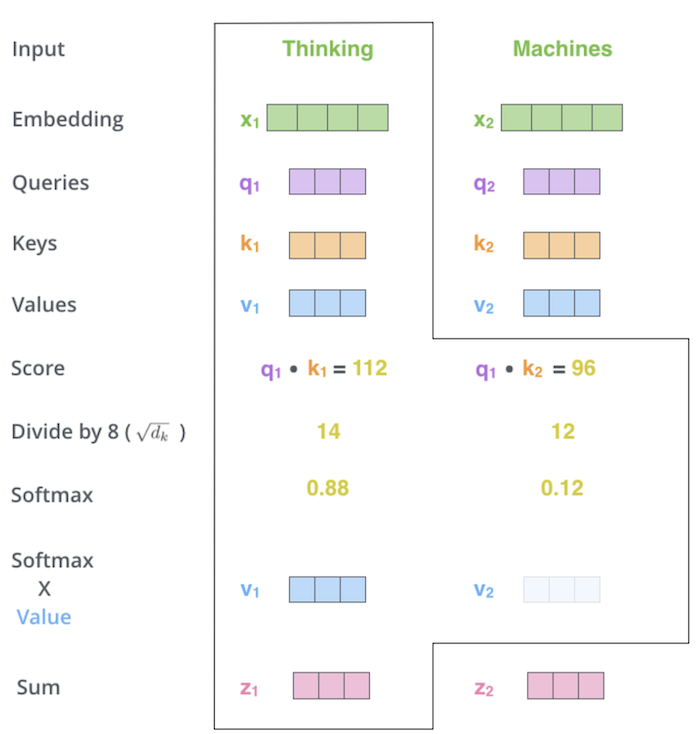
(optional) implementation details
multi-headed attention - just like having many filters, get many encodings for each word
each one can take input as the embedding from the previous attention layer
position vector - add this into the embedding of each word (so words know how far apart they are) - usually use sin/cos rather than actual position number
padding mask - add zeros to the end of the sequence
look-ahead mask - might want to mask to only use previous words (e.g. if our final task is decoding)
residual + normalize - after self-attention layer, often have residual connection to previous input, which gets added then normalized
decoder - each word only allowed to attend to previous positions
3 components
queries
keys
values
attention
encoder reads input and ouputs context vector after each word
decoder at each step uses a different weighted combination of these context vectors
specifically, at each step, decoder concatenates its hidden state w/ the attention vector (the weighted combination of the context vectors)
this is fed to a feedforward net to output a word
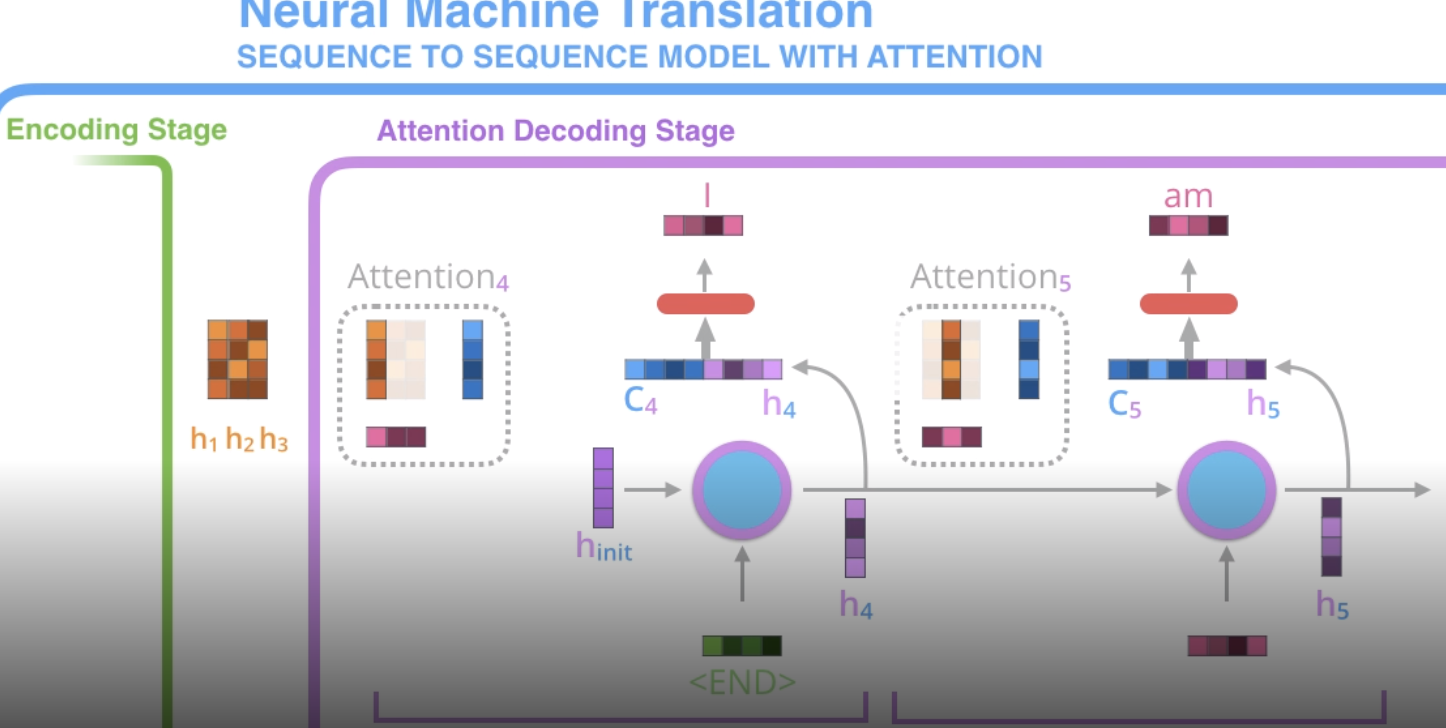
at a high level we have \(Q, K, V\) and compute \(\text{softmax}(QK^T)V\)
instead could simplify it and do \(\text{softmax}(XX^T)V\) - this would then be based on kernel
transformer
uses many self-attention layers
many stacked layers in encoder + decoder (not rnn: self-attention + feed forward)
details
initial encoding: each word -> vector
each layer takes a list of fixed size (hyperparameter e.g. length of longest sentence) and outputs a list of that same fixed size (so one output for each word)
can easily train with a masked word to predict the word at the predicted position in the encoding
multi-headed attention has several of each of these (then just concat them)
1.9.5.3. huggingface tutorial#
Broadly, models can be grouped into three categories:
GPT-like (also called auto-regressive Transformer models)
BERT-like (also called auto-encoding Transformer models)
BART/T5-like (also called sequence-to-sequence Transformer models)
Handling multiple sequences - Hugging Face Course
pad sequences to have the same length (need to modify attention masks to ignore the padded values)
1.9.5.4. pre-transformer nlp models#
rnns
when training rnn, accumulate gradients over sequence and then update all at once
stacked rnns have outputs of rnns feed into another rnn
bidirectional rnn - one rnn left to right and another right to left (can concatenate, add, etc.)
standard seq2seq
encoder reads input and outputs context vector (the hidden state)
decoder (rnn) takes this context vector and generates a sequence