2.1. info retrieval#
2.1.1. introduction#
building blocks of search engines
search (user initiates)
reccomendations - proactive search engine (program initiates e.g. pandora, netflix)
information retrieval - activity of obtaining info relevant to an information need from a collection of resources
information overload - too much information to process
memex - device which stores records so it can be consulted with exceeding speed and flexibility (search engine)
IR pieces
Indexed corpus (static)
crawler and indexer - gathers the info constantly, takes the whole internet as input and outputs some representation of the document
web crawler - automatic program that systematically browses web
document analyzer - knows which section has what -takes in the metadata and outputs the index (condensed), manage content to provide efficient access of web documents
User
query parser - parses the search terms into managed system representation
Ranking
ranking model -takes in the query representation and the indices, sorts according to relevance, outputs the results
also need nice display
query logs - record user’s search history
user modeling - assess user’s satisfaction
steps
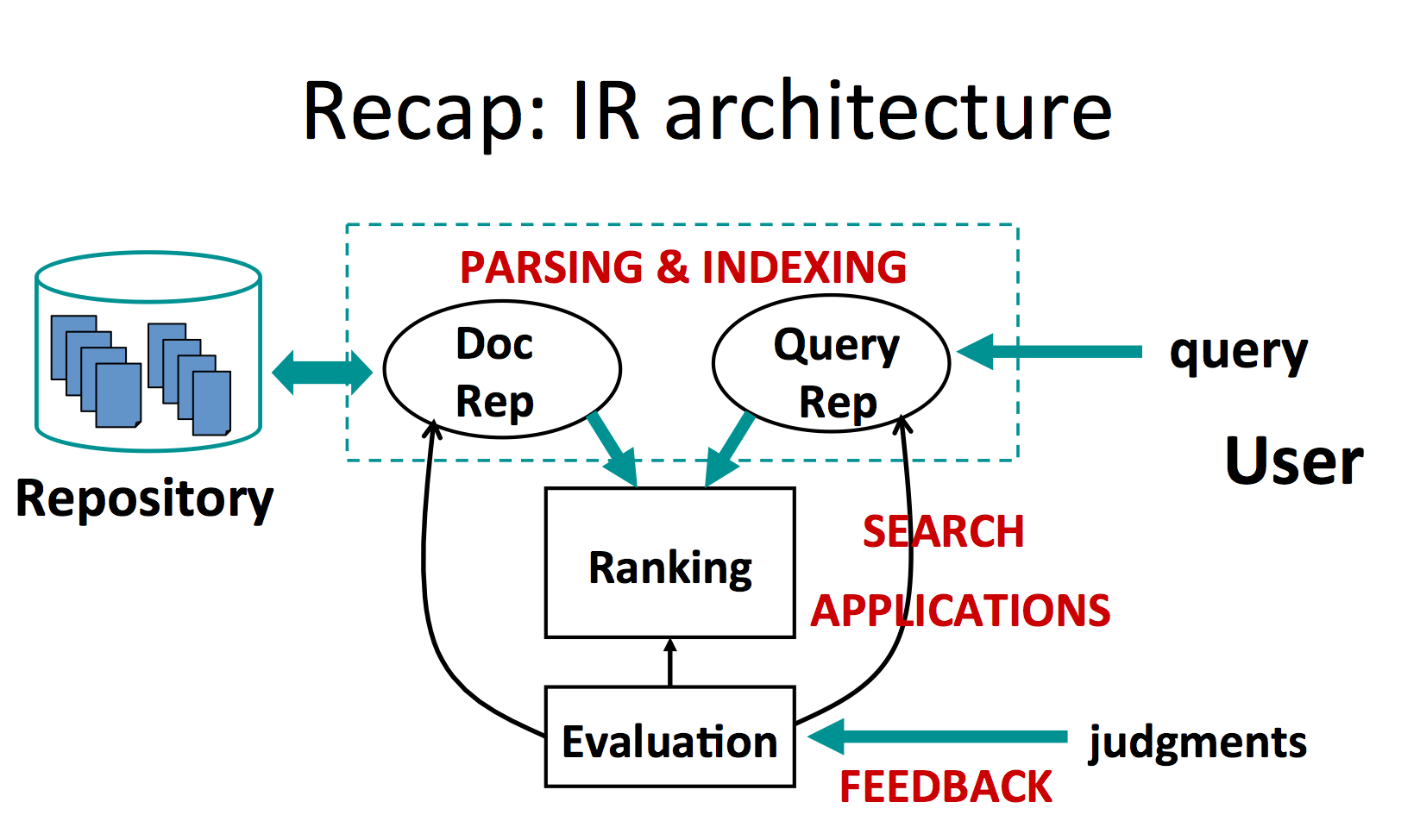
repository -> document representation
query -> query representation
ranking is performed between the 2 representations and given to the user
evaluation - by users
information retrieval:
reccomendation
question answering
text mining
online advertisement